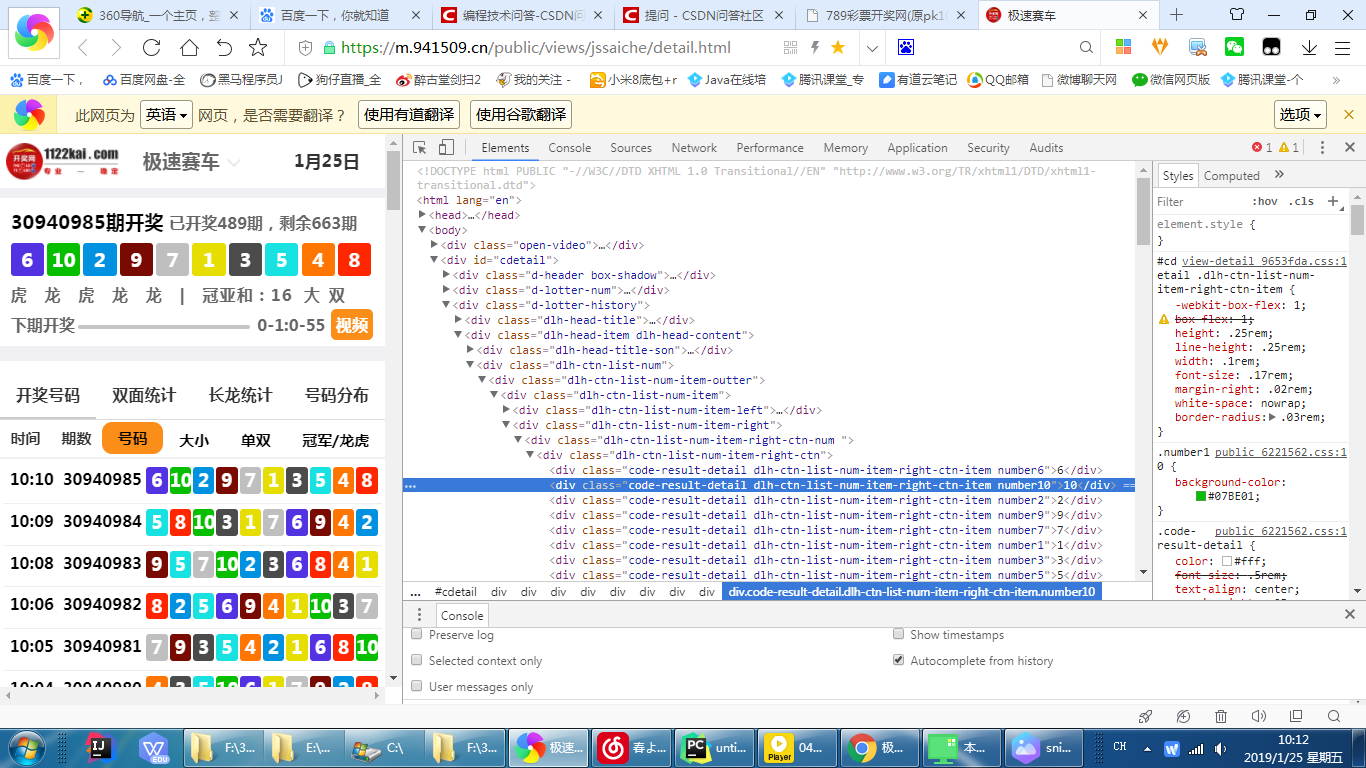
怎么爬取最近5期数字?帮忙看一下哪里写的不对请指教
怎么爬取最近5期数字? 爬的是空壳[],帮忙看一下哪里写的不对请指教
是不是json格式,需要动态Ajax加载页面爬
import re
import requests
def parse_page(url):
headers = {
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36"
}
response = requests.get(url,headers)
text = response.text
titles = re.findall(r'
.*?
print(titles)
# dynasties = re.findall(r'
poem_tags = re.findall(r'
print(poem_tags)
(.*?)
',text,re.S) #dlh-ctn-list-numx dlh-ctn-list-num-item-outterprint(titles)
# dynasties = re.findall(r'
.*?(.*?)',text,re.S)
# authors = re.findall(r'
.*?(.*?)',text,re.S)
# poem_tags = re.findall(r'
(.*?)
',text,re.S) #dlh-ctn-list-num-item-rightpoem_tags = re.findall(r'
(.*?)
', text, re.DOTALL)print(poem_tags)
def main():
url = "https://m.941509.cn/public/views/jssaiche/detail.html"
parse_page(url)
if name == '__main__':
main()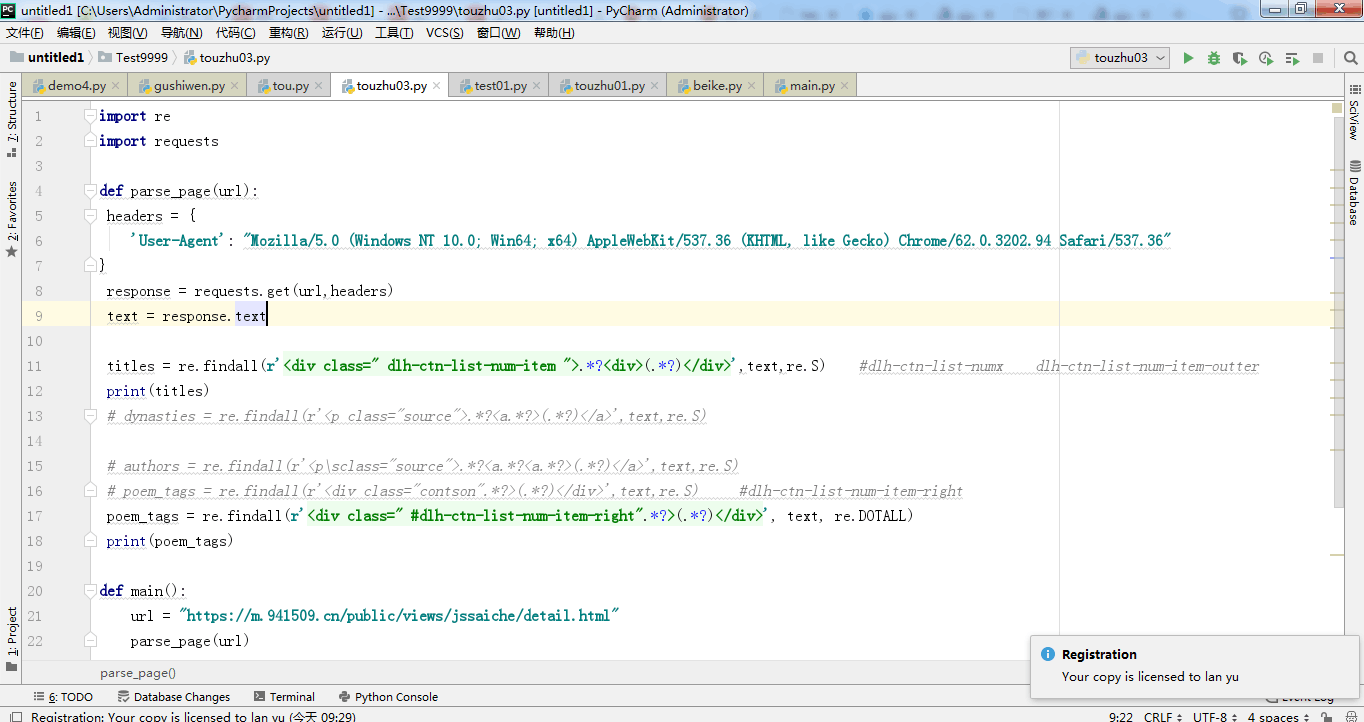
爬的是空壳[]
动态Ajax加载页面怎么爬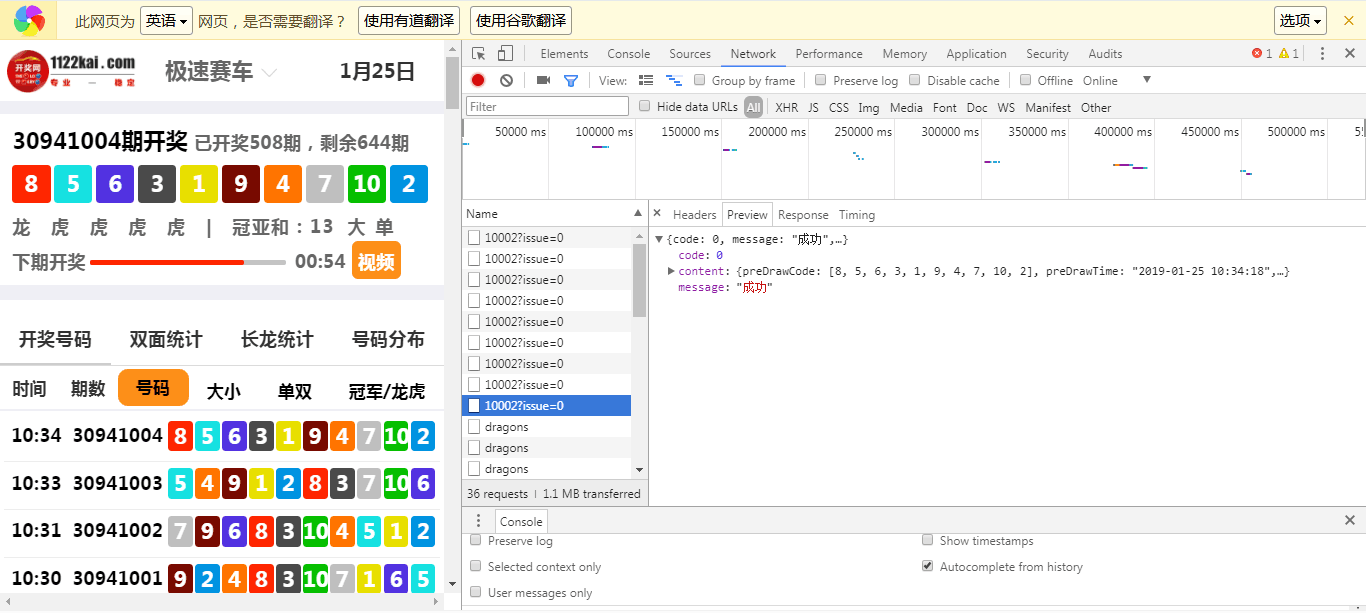
直接取出他们的父标签,遍历五次不就好了吗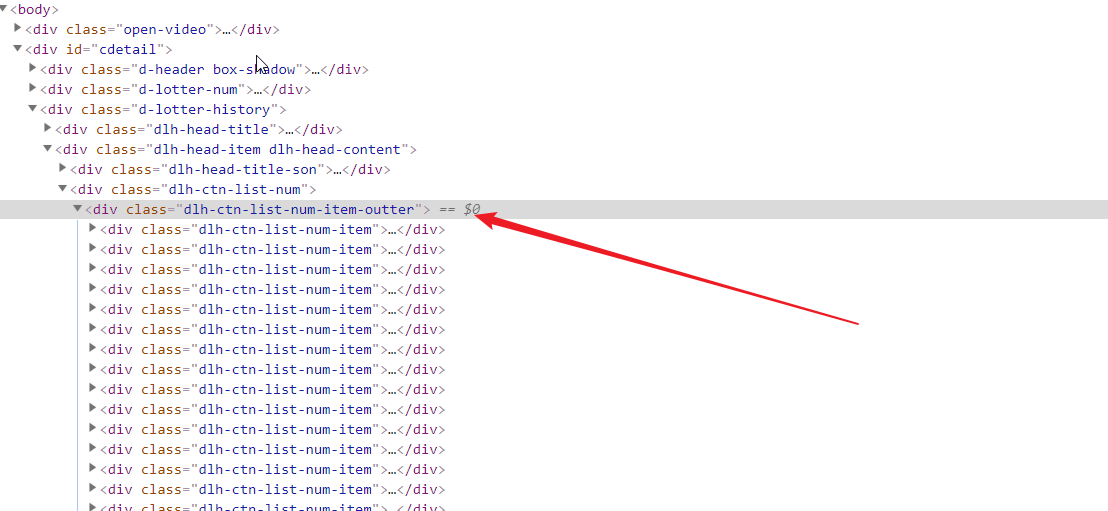
←如果以下回答对你有帮助,请点击右边的向上箭头及采纳下答案
以下代码通过动态Ajax加载页面爬取,经测试会有时候返回服务器请求失败,估计是服务器只能间歇性请求,可以找下请求通过时间的间隔做下调整
s=requests.session()
headers = {
'Referer': 'https://m.941509.cn/public/views/jssaiche/detail.html',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.15 Safari/537.36',
}
s.headers.update(headers) ##加入请求头
html=s.get('https://m.941509.cn/public/views/jssaiche/detail.html') ##增加这个请求成功率有增加 ,不知道为什么
print(html)
url='https://api.950021.com/lottery-client-api/races/10002/history?date=' ##请求网址
js=s.get(url=url,timeout=60).json() ##请求json结果
#print(js)
content=js['content'] ##json内content的值
for i in content[0:5]: ##前5期的值
print(i['preDrawCode'])