只要有一个单词未出现在句子中,就不用匹配下一个单词,而是停止匹配这个句子转而匹配下一个句子。
表一
表二 、
、
我之前实现的代码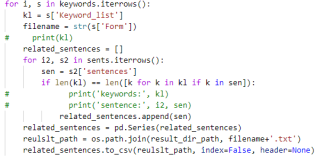
我通过Keyword_list里面的关键词,来查找匹配sentences,然后把匹配过后的sentences输入到以Form 命名的txt文件当中。
我原本的做法是来计算关键词list的长度,然后搜索提取sentences里面的关键词之后计算长度,如果相等就输出。但是这样做的话,相当于是每一个关键词list里面的单词都参与了计算,我的sentences表有200多万条数据,花费的时间很长,浪费了很多算力。
我现在的想法是,能不能在匹配的时候,关键词list里的每一个单词参与匹配,但是如果有一个关键词没有出现,就跳过正在匹配的这个句子,只输出关键词数量对等的句子。比如说表二的第一行是['ent, 'federal','credit], 如果在匹配句子的时候,ent没有出现,那么'federal',’credit‘就没有必要继续匹配了,而是跳到表一的下一条句子进行匹配。
朋友们,我的新想法该如何实现呢?我实在是有点想不到了。
for sentence in sentences:
f = True
for keyword in Keyword_list:
if not keyword in sentence:
f = False
if f:
print(sentence)
很简单,
1)准备阶段
先把sentences里的每个sentence排个序,比如s = ['xyz', 'abc', 'mmmf'],排序之后sorted(a)的结果是['abc', 'mmmf', 'xyz']。对keyword_list里的每个keyword也同样排序,最后再把sentences整个儿排个序:sentences = sorted(sentences)
2)搜索阶段
使用包bisect.bisect_left()进行二分查找即可。
示例:
from bisect import bisect_left
sentences = [['a', '12'], ['666', '999', '888'], ['_4rr', '588'], ['_3dd', 'uUU']]
keyword_list = [['588', '_4rr'], ['a', '12'], ['123', 'xyz']]
sentences = [sorted(s) for s in sentences]
sentences = sorted(sentences)
length = len(sentences)
for kw in keyword_list:
kw = sorted(kw)
i = bisect_left(sentences, kw)
if i < length and sentences[i] == kw:
print("%d: %s" % (i, sentences[i]))
如果采用了我的答案,请点击“采用”。