tensorflow 实现 DQN2013版 计算max(Q(snext))代码问题

DQN中误差计算是由上式的均方误差来定义的,我的神经网络的输出是Qeval,是Action个q值,但是我在用tensenflow代码实现max(Q(snext)) 时遇到了问题,就是我有两个版本
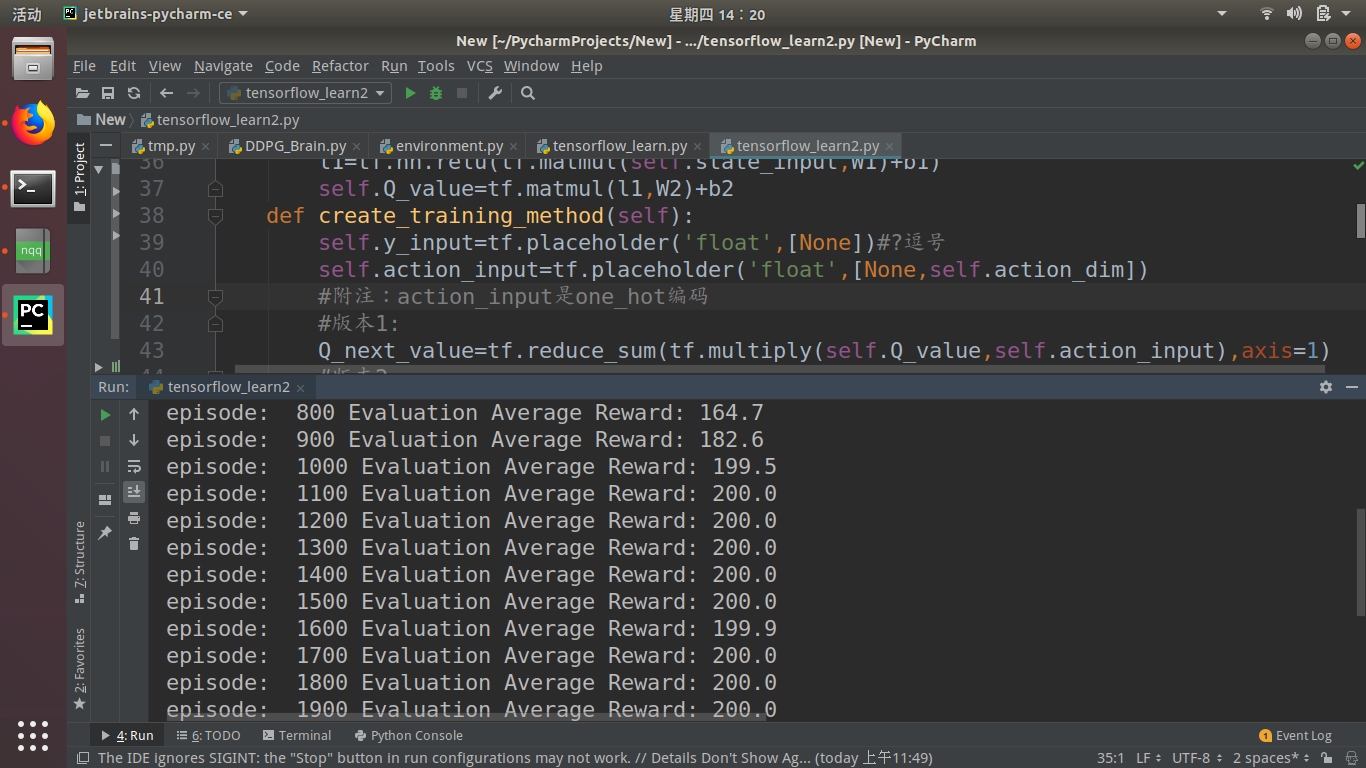
版本一用one-hot编码动作,然后用动作和Qeval向量相乘的到max(Q(snext))
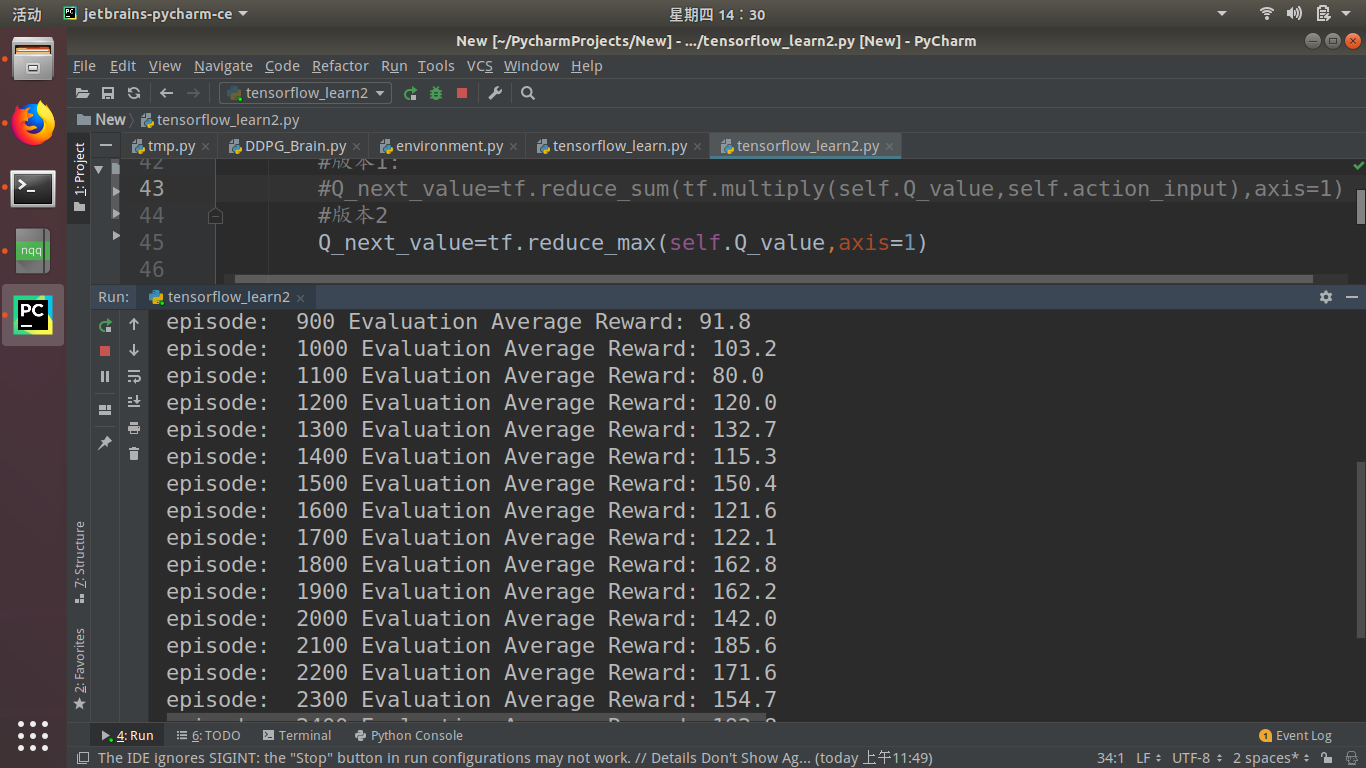
版本二没有使用动作,直接用tf.reduce mean(Qeval,axis=1)来直接得到max(Q(snext))。
那么问题来了:(每训练100步,然后再测试十次取平均,使用的gym.cartPole-v0环境)我用版本一,大约第1100回合就可以达到200分。
我用版本二,效果却相差有点大。我想问:这两个版本的计算效果都是一样的,可为什么效果却差很多呢(运行了多次,结果都一样)?