selenium判断网页是否存在标签问题
from datetime import time
from lxml import etree
import time
import requests
from selenium import webdriver
p = input('请输入问题:')
driver = webdriver.Chrome(executable_path="D:\桌面\编程\python\环境变量\chromedriver.exe")
driver.get('https://www.baidu.com')
driver.find_element_by_id("kw").send_keys("site:zhidao.baidu.com " + p)
driver.find_element_by_id("su").click()
driver.find_element_by_id("su").click()
time.sleep(1)
elem1 = driver.find_element_by_link_text("百度知道")
elem1.click()
time.sleep(2)
# 切换当前标签
driver.switch_to.window(driver.window_handles[1])
# 用这个获取url
print(driver.current_url)
time.sleep(1)
url = driver.current_url
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36 Edg/91.0.864.67'
}
r = requests.get(url, headers=headers)
r.encoding = 'gbk'
html = etree.HTML(r.text)
try:
driver.find_element_by_xpath('//div[@class="best-text mb-10"]')
print("存在1")
i = html.xpath('//div[@class="best-text mb-10"]/text()')
p = ''.join(i)
print(p)
driver.find_element_by_xpath("//div[@class='answer-text mb-10']")
print("存在2")
i = html.xpath('//div[@class="line content')
print(i)
p = ''.join(i)
print(p)
driver.find_element_by_class_name('line content')
print('存在3')
i = html.xpath('//div[@class="line content')
print(i)
p = ''.join(i)
print(p)
except:
print("不存在")
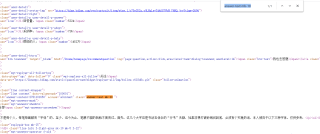
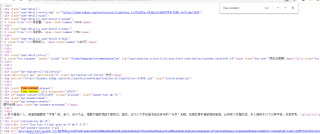
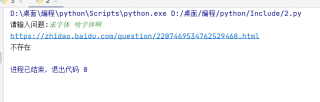
网页是存在后两个标签的不知道为什么判断网页标签不存在,
存在1 的打印输出也没有,肯定是 driver.find_element_by_xpath('//div[@class="best-text mb-10"]') 就程序异常了