Expecting value:line1column1(char 0)
爬虫时进行Response中的json数据提取,将返回内容转化为dic类型时报 Expecting value: line 1 column 1 (char 0)错。
问题代码如下:
import requests
import json
import jsonpath
url = "http://www.zgei.com/?name=%E6%88%91%E6%83%B3%E8%A6%81&type=qq"
r = requests.get(url=url,timeout=3)
if r.content != None:
data = json.loads(r.content.decode('utf-8-sig'))
#这里将解码成utf-8-sig 是因为会报unexpected utf-8 bom (decode using utf-8-sig) line 1 column 1 (char 0)错误
完整报错代码如下:
Traceback (most recent call last):
File "D:/pythonProject/Music_Download/1000.py", line 10, in <module>
data = json.loads(r.content.decode('utf-8-sig'))
File "D:\Python\lib\json\__init__.py", line 357, in loads
return _default_decoder.decode(s)
File "D:\Python\lib\json\decoder.py", line 337, in decode
obj, end = self.raw_decode(s, idx=_w(s, 0).end())
File "D:\Python\lib\json\decoder.py", line 355, in raw_decode
raise JSONDecodeError("Expecting value", s, err.value) from None
json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
json.loads()报错
查了好多种方法都还是报这个错,有说url不对应,改了也不好使,实在不知道那里的问题!!
你访问的网址返回的是html代码,不是json格式字符串当然出错了。内容是post请求的http://www.zgei.com/接口发送参数。
有帮助麻烦点个采纳【本回答右上角】,谢谢~~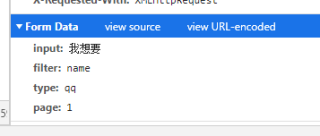
示例代码如下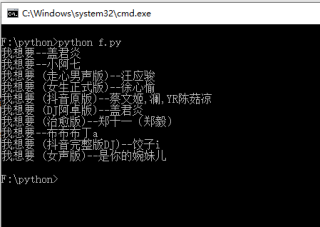
import requests
headers={
"Referer": "http://www.zgei.com/?name=%E6%88%91%E6%83%B3%E8%A6%81&type=qq",
"X-Requested-With":"XMLHttpRequest",
"Referrer Policy":"strict-origin-when-cross-origin"
};
data={"input":"我想要","filter":"name","type":"qq","page":1};
r=requests.post("http://www.zgei.com/",headers=headers,data=data)
data=r.json()
if data["code"]==200:
for song in data["data"]:
print(song["title"]+"--"+song["author"])
else:
print(data)
把json数据打印出来看看,应该是不符合json规范的字符串。