python爬虫为何得不到数据
很简单的一个url:http://jckspj.customs.gov.cn/spj/zwgk75/2706880/jckrljgzyxx33/2812399/index.html,为何我没有获取到,这不是js动态生成的页面啊,我只想获取这几个链接的url,但是request返回一堆js是怎么回事 。
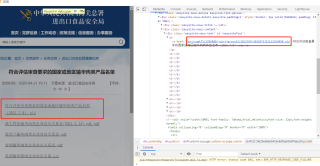 ,
,
网站设置有debugger反爬,不允许页面调试,需要寻找相应的解决办法哦,望采纳
我拿selenium 可以取到数据,但是我采用静默模式为何就只得到这个结果:<"html><"head><"/head><"body><"/body><"/html>"
你这headers也没加上啊。。
headers={
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,/;q=0.8',
'Accept-Encoding':'gzip, deflate',
'Accept-Language':'zh-CN,zh;q=0.9',
'Cache-Control':'max-age=0',
'Cookie':'9CKCOkIaqzqES=5uqJUOv9DzBJ0QWdxmwLgNtF1qpU6rSVse7co9G5sshYgZnp_9DGZ.X1Ul6iP_tmNesW_f_wCL3ca3uCV5nKzHq; EPORTALJSESSIONID=TbioTJnbyEw87rQ3OERf-9ot6CeUxc5Pv-JbkSGalboU1sxp5TG2!1491495028; 9CKCOkIaqzqET=5F8FgpDvbX53xcAfuLVKs5aw.3fl2pDUTIxXpBYFdrh_4_Y1ENj_jsLIrXzQwMddb9VK4WELG_XL4lW1f1KIpXSuMz4Lxb8PMEeuW4eIFYum1h6OCDS9NseKLHbQQ4IvXbe4IsezUsKz_AxqCvSFGfjcaIKxGMgvUBtZFTd8xXgYQ.UMLQWz0XYp0OnkkjjnFnBZcGoDCZcniFKKMgZ5a0inmiqSz2tWNgiB7vcNX9m45IK3AQpWOyV.IzKEMmaWNZvUE697HCdninmFtTowF3tgzUO_ept2OjG5hQtM7uCpJSpzXHA_f15mXCiMYC5wLa; gwdshare_firstime=1626321648648; _gscu_597121699=26321648xl7xkf49; _gscbrs_597121699=1; _gsref_597121699=http://jckspj.customs.gov.cn/spj/zwgk75/2706880/jckrljgzyxx33/2812399/index.html; _gscs_597121699=26321648bns5h849|pv:1',
'Host':'jckspj.customs.gov.cn',
'Proxy-Connection':'keep-alive',
'Upgrade-Insecure-Requests':'1',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36',
}
resp = requests.get(url,headers=headers)
直接拿去用 不谢 给我好评