python中read()函数会丢失txt文本数据的问题
下面是出错部分的代码

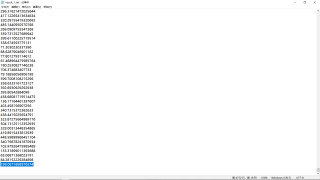
导入的result文件截图,共有4752行数据(如下图)
result文件总共有4752行数据,但是,通过read()函数读取之后,只剩下了4652行(如下图)
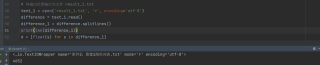
后面的100行数据读取不到,导致后面的代码出错,下面是读取到的第4652行数据,我没发现有什么问题

请问我该如何解决这个问题?
问题已经解决,前面生成文本数据的循环没有结束,程序就已经进入了读取文件的阶段,导致后面的读不全,我第一遍运行的时候超出,第二遍我把前面生成文本的部分注释掉,因为此时文本内的数据已经在第一遍运行时生成完毕,所以第二遍读取就不会超出了。
读取方式上改成:with open() as f:省去了f.close(),在读取时,使用readlines或用read读取到的分割成列表。
with open('vt.txt','r',encoding='utf8') as f:
data=[x for x in f.read().strip().split('\n')]
print(len(data))
def read_text_file(filePath):
txt_content = []
with open(filePath, 'r', encoding='utf-8-sig') as file_object:
while True:
content = file_object.readline()
if not content:
break
line = content.strip('\n')
txt_content.append(line)
return txt_content
检查原文档是不是有空行
请问具体怎么解决的呢?我也遇到数据读取不全的问题。想先读取,再写入一个新的txt文档里面,但是数据不全
