pandas 有没有方法将这几个列组成一个条件,然后计算出符合这个条件的行的行数
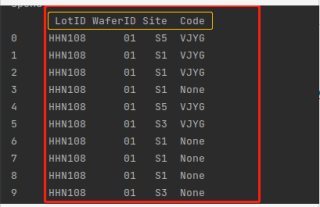
相当于计算出每一行都相同的数据的条数
相当于计算出每一行都相同的数据的条数
有没有大佬能指点一二
df.groupby(['LotID','WaferID','Site','Code']).size()
是去除重复吗?
@weixin_45864635
不只是去重,需要计算出每一行的数量, 然后新增一列来保存这个数量

相当于计算出每一行都相同的数据的条数
相当于计算出每一行都相同的数据的条数
有没有大佬能指点一二
df.groupby(['LotID','WaferID','Site','Code']).size()
是去除重复吗?
@weixin_45864635
不只是去重,需要计算出每一行的数量, 然后新增一列来保存这个数量