如何把df.values.count的结果转化成表格?

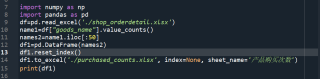
我统计了excel中一列的频数。但是我现在想把这个结果以表格的形式写进excel,表格的第一列是商品名称,第二列是频数
使用pandas中数组转数据框函数to_frame()即可。构造了一个简单数据框并示例如下。
import pandas as pd
df=pd.DataFrame({'name':['a','b','c','c','d','a','b','a'],'num':[1,1,1,1,1,1,1,1]})
res=df.groupby('name')['num'].count().to_frame().reset_index()
res.to_excel('test3.xlsx')
如对你有帮助,请点击我回答的右上方采纳按钮,采纳一下~~
戴噶猴,我又来了。我发现我的基础知识真的有问题。。。本来我在总结apply呢,然后第一段代码就报错。遇到了一万次TypeError: sort_values() got an unexpected keyword argument 'by'这个报错后,终于忍不住总结一波了。恍然大悟,还请大佬们多多指教!结合df+series+rename这篇一起看吧~#!/usr/bin/env python
-- coding:utf8 --
@TIME :2018/11/3 16:23
@Author:Yolanda
@File :temp8.py
#反击啊!少女
from pandas import DataFrame as DF
import pandas as pd
data=pd.DataFrame({'A':[1,2,3,4],'B':[5,6,6,8],'C':[9,9,9,12]})
def column_types_table(data):
print('Number of each type of columns:')
count_dtype = data.dtypes.value_counts().reset_index()#总表每一类别总数,以列为单位
count_dtype.columns = ['name','total']
print(count_dtype)
print('\nNumber of unique classes in each columns:')
for i in count_dtype['name'].values:
print('Type: ',i)#计算每一列不同类型的个数
print(type(data.select_dtypes(i).nunique()))#<class 'pandas.core.series.Series'>
print(type(data.select_dtypes(i).nunique().reset_index(drop=True)))#<class 'pandas.core.series.Series'>。注意!!
print(type(data.select_dtypes(i).nunique().reset_index()))#<class 'pandas.core.frame.DataFrame'>
# reset_index()之后,series会强制转换为df,df还是df。
# reset_index(drop=True)之后,series还是series,df还是df。
# 第一种写法:series
print(data.select_dtypes(i).nunique())
# A 4
# B 3
# C 2
# dtype: int64
# 第二种写法:df,所以有默认列名
print(data.select_dtypes(i).nunique().reset_index())
# index 0
# 0 A 4
# 1 B 3
# 2 C 2
# 第三种写法:series
print(data.select_dtypes(i).nunique().reset_index(drop=True))
# 0 4
# 1 3
# 2 2
# dtype: int64
# 第四种写法:df,修改默认列名0为nunique
print(data.select_dtypes(i).nunique().reset_index().rename(columns={0:'NUNIQUE'}))
# index NUNIQUE
# 0 A 4
# 1 B 3
# 2 C 2
# 第五种写法:series,rename没用,rename对于df才有用
print(data.select_dtypes(i).nunique().reset_index(drop=True).rename(columns={0:'NUNIQUE'}))
# 0 4
# 1 3
# 2 2
# dtype: int64
# 第六种写法:对于df,没有rename列名,那sort_values用法是sort_values(by=[0]),默认升序
print(data.select_dtypes(i).nunique().reset_index().sort_values(by=[0],ascending=False))
# index 0
# 0 A 4
# 1 B 3
# 2 C 2
# 第七种写法:对于df,rename列名后,那sort_values用法是sort_values(by=['列名']),默认升序
print(data.select_dtypes(i).nunique().reset_index().rename(columns={0:'NUNIQUE'}).sort_values(by=['NUNIQUE'],ascending=False))
# index NUNIQUE
# 0 A 4
# 1 B 3
# 2 C 2
# 第八种写法:对于df,没有rename列名,那sort_values用法是sort_values(by=[0]),默认升序,可以最后再rename列名
print(data.select_dtypes(i).nunique().reset_index().sort_values(by=[0], ascending=False).rename(columns={0: 'NUNIQUE'}))
# index NUNIQUE
# 0 A 4
# 1 B 3
# 2 C 2
# 第九种写法:对于series,rename没用,那sort_values用法是sort_values(0),默认升序
print(data.select_dtypes(i).nunique().reset_index(drop=True).rename(columns={0:'NUNIQUE'}).sort_values(0,ascending=False))
# 0 4
# 1 3
# 2 2
# dtype: int64
# 第十种写法:等价于第八种写法,结尾再drop也没用
print(data.select_dtypes(i).nunique().reset_index().sort_values(by=[0], ascending=False).rename(columns={0: 'NUNIQUE'}).reset_index(drop=True))
# index NUNIQUE
# 0 A 4
# 1 B 3
# 2 C 2
# 第十一种写法:等价于第八种写法,只不过这么写可以不加重复index,因为加了drop=True就变成series了,没法放列名,而不加drop=True,可以加列名又不能去掉重复index。
# 也就是不使用reset_index来转化为df,直接使用DF,不会多加index。apply(pd.Series.nunique, axis=0)的axis=0可以不加,默认按行,如果等于1,就是按列
print(DF(data.select_dtypes(i).apply(pd.Series.nunique, axis=0)). \
sort_values(by=[0], ascending=False).rename(columns={0: 'NUNIQUE'})) # 按列0排序,没有给名字的时候,转化成df是自动命名01234
# NUNIQUE
# A 4
# B 3
# C 2
# 第十二种写法:等价于第十一种写法,直接使用DF,不会多加index。
# nunique()等价于nunique(axis=0)等价于apply(pd.Series.nunique)等价于apply(pd.Series.nunique, axis=0),改成1就是按列。
print(DF(data.select_dtypes(i).nunique()).sort_values(by=[0], ascending=False).rename(columns={0: 'NUNIQUE'}))
# NUNIQUE
# A 4
# B 3
# C 2
column_types_table(data)总结: 一、rename1、 df,所以有默认列名,rename可用 2、 series,无默认列名,rename没用 二、apply1、nunique()等价于nunique(axis=0)等价于apply(pd.Series.nunique)等价于apply(pd.Series.nunique, axis=0),改成1就是按列。三、 sort_values1、 对于df,没有rename列名,那sort_values用法是sort_values(by=[0]),默认升序,可以最后再rename列名 2、 对于df,rename列名后,那sort_values用法是sort_values(by=['列名']),默认升序 3、 对于series,rename没用,那sort_values用法是sort_values(0),默认升序 四、 转换类型1、 reset_index()之后,series会强制转换为df并多加了一列index,df还是df。 2、 reset_index(drop=True)之后,series还是series,df还是df。 3、 直接使用DF转换为df,不会多加index。from pandas import DataFrame as DF