请教一下各位,stata回归分析的结果应该怎么看呀?
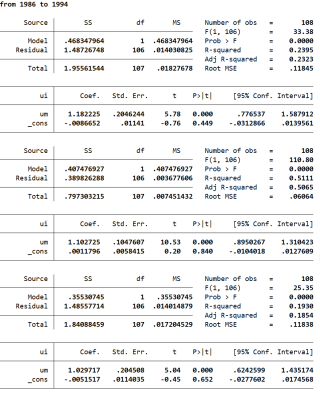 df,t,p>绝对值t分别代表什么呀?
df,t,p>绝对值t分别代表什么呀?
在 Stata 中,进行回归分析后,我们通常要关注的是回归系数、截距、 R-squared 等指标,以判断模型的解释力、拟合效果。以下是具体的解释说明:
- 回归系数(Coefficients) 回归系数是各个自变量在模型中的贡献值。回归系数可以用于评估不同的自变量对因变量的影响,正系数表示自变量与因变量正相关;负系数则表示二者之间存在负相关关系。可以通过 reg 命令的输出结果中的 Coefficients 列来查看。
- 常数项(Intercept) 常数项是指截距项,表示当所有自变量为 0 时,因变量的期望值。可以通过 reg 命令的输出结果中的 Intercept 列来查看。 3. R-squared R-squared 是用于衡量拟合效果的指标,表示因变量的方差被自变量解释的比例,也称为拟合度或解释度。R-squared 的值越接近于 1,表示回归模型的解释力和预测力越好。可以通过 reg 命令的输出结果中 R-squared、Adjusted R-squared 来查看。
- 标准误差(Standard Error) 标准误差是用于衡量估计量精度的指标,表示样本均值与总体均值之间的差异。标准误差越小,表示回归系数的估计值越精确。可以通过 reg 命令的输出结果中的标准误差列来查看。
- t 值和 P 值(t-value, P-value) t 值和 P 值是用于判断变量是否对因变量存在显著性影响的指标。t 值表示回归系数相对于其标准误差的比值,大于 2 或小于 -2 时即为显著,通常也可以查看其对应的 P 值,P 值小于 0.05 或 0.01 时,也表明回归系数的显著性存在统计学意义上的意义。可以通过 reg 命令的输出结果中的 t 列和 P 列来查看。
以上是 Stata 中回归分析的常见结果指标解释,需要根据实际情况选择查看哪些指标来评估回归模型的拟合效果和解释力。同时需要注意,以上指标只是评估回归模型的一些常用手段,如何利用回归结果,并不是一成不变,而需要结合实际情况,合理选择。