python中with open写入错误
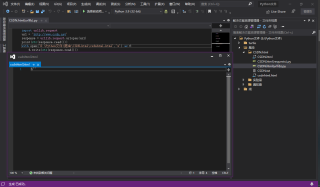
import urllib.request
url = 'http://www.csdn.net'
response = urllib.request.urlopen(url)
print(str(response.read()))
with open('E:\Python文件\爬虫\CSDN.html\csdnhtml.html','w') as f:
f.write(str(response.read()))
问题:为什么会写入“ b'' ”?不应该写入csdn的html源代码吗?怎么处理?
import requests
url = 'http://www.csdn.net'
r = requests.get(url)
with open('E:\Python文件\爬虫\CSDN.html\csdnhtml.html','w',encoding='utf-8') as f:
f.write(r.text)
response.read()返回的是 bytes 类型数据吧,是不是要转换一下再存储?参考https://blog.csdn.net/chengqiuming/article/details/85931725
我也没怎么用过urlopen,不是很清楚