tensorflow keras训练过程中,输出正确率和损失函数值都为0,这个是哪里出问题了
### 生成数据集代码:
> 数据集是满足x*x < y的
import random
def line_split():
with open("dataset/line_split.txt", "w", encoding="utf-8") as f:
num = 1000
s = []
for i in range(num):
x = random.random()*10
y = random.random()*20
if x*x < y:
if i != (num-1):
s.append("{},{},{}\n".format(x, y, 1))
else:
s.append("{},{},{}".format(x, y, 1))
else:
if i != (num - 1):
s.append("{},{},{}\n".format(x, y, -1))
else:
s.append("{},{},{}".format(x, y, -1))
f.writelines(s)
### 加载数据代码:
def s2f(num):
return float(num)
def load_data(file_name):
with open(file_name, "r", encoding="utf-8") as f:
lines = f.readlines()
x, y = [], []
for line in lines:
data = list(map(s2f, line.split(",")))
x.append(data[:-1])
y.append(data[-1])
return x, y### 源代码:
import tensorflow as tf
import load_data
x, y = load_data.load_data("dataset/line_split.txt")
x = tf.cast(x, dtype=tf.float32)
y = tf.cast(y, dtype=tf.int32)
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(
2,
activation="softmax",
kernel_regularizer=tf.keras.regularizers.l2() # 正则化
)]
)
model.compile(
optimizer=tf.keras.optimizers.SGD(lr=0.5),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['binary_accuracy']
)
model.fit(x, y, batch_size=32, epochs=100, validation_split=0.2, validation_freq=20)
model.summary()
### 很奇怪,所有的loss和准确率都为0,这个是为什么???
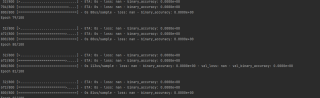
请问解决了吗?求帮助