pandas groupby 最大最小值
给定2个csv文件 score.csv zhiwu.csv

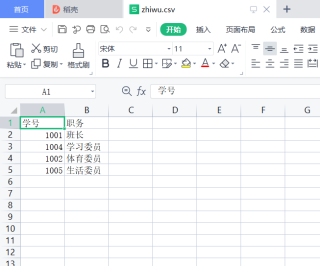
(1) score对象新增一列“总分”,值为前三列成绩之和。
(2) score对象依据“总分”列的值从高到低进行排序。
(3) score对象根据“性别”列进行分组,输出男生、女生各自的平均成绩。
(4) 输出男生的最高总分、女生的最低总分。
(5) score对象新增一列“等级”,总分大于等于270的等级为A,总分小于210分的等级为C,总分介于210到270的等级为B。
(6) 使用merge()函数以“学号”列为关键主键,将score对象与zhiwu对象合并,合并时保留score对象的所有数据行,合并后生成一个新的DataFrame对象students。以students的“学号”列作为新索引,打印输出students。
用pandas对数据进行处理。
df1<span class="hljs-selector-attr">[<span class="hljs-string">'总分'</span>]</span>=df1<span class="hljs-selector-attr">[[<span class="hljs-string">'思政'</span>,<span class="hljs-string">'微积分'</span>,<span class="hljs-string">'大学英语'</span>]</span>]<span class="hljs-selector-class">.sum</span>(axis=<span class="hljs-number">1</span>)
df1=df1<span class="hljs-selector-class">.sort_values</span>(by=<span class="hljs-string">'总分'</span>,ascending=False,ignore_index=True)
groups=df1<span class="hljs-selector-class">.groupby</span>(<span class="hljs-string">'性别'</span>)<span class="hljs-selector-attr">[<span class="hljs-string">'总分'</span>]</span><span class="hljs-selector-class">.apply</span>(lambda x:sum(x)/len(x))
df1<span class="hljs-selector-attr">[df1[<span class="hljs-string">'性别'</span>]</span>==<span class="hljs-string">'男'</span>]<span class="hljs-selector-attr">[<span class="hljs-string">'总分'</span>]</span><span class="hljs-selector-class">.sort_values</span>()<span class="hljs-selector-class">.to_list</span>()<span class="hljs-selector-attr">[-1]</span>
df1<span class="hljs-selector-attr">[df1[<span class="hljs-string">'性别'</span>]</span> == <span class="hljs-string">'女'</span>]<span class="hljs-selector-attr">[<span class="hljs-string">'总分'</span>]</span><span class="hljs-selector-class">.sort_values</span>()<span class="hljs-selector-class">.to_list</span>()<span class="hljs-selector-attr">[0]</span>