关于python re模块的使用
我们可以通过下面的代码导入re库
import re1. 使用match()方法进行匹配
match()方法用于从字符串的开始处进行匹配,如果在起始位置匹配成功,则返回Match对象,否则返回None,语法如下
re.match(pattern, string, [flags])
pattern:表示模式字符串,由要匹配的正则表达式转换而来
string:表示要匹配的字符串
flags:可选参数,表示标志位,用于控制匹配方式,如是否区分字母大小写。
比如匹配字符串是否以"py"开头,不区分大小写代码如下
import re
pattern = r'py\w+'
string = 'python is PYTHON'
match = re.match(pattern, string, re.I) # re.I表示不区分大小写
print(match)
string = "这是python"
match = re.match(pattern, string, re.I)
print(match)
因为match是用字符串的开头开始匹配的,因为"这是python"这个字符串不是py开始的。所以返回的是None。span这个元组表示匹配的位置,第一个为开始位置,第二个为结束位置。
import re
pattern = r'py\w+'
string = 'python is PYTHON'
match = re.match(pattern, string, re.I) # re.I表示不区分大小写
print(match)
print("匹配的起始位置:", match.start())
print("匹配的结束位置:", match.end())
print("匹配的元组:", match.span())
print("匹配的字符:", match.string)
print("匹配的数据:", match.group())
2. 使用search()方法进行匹配
search()方法用于在整个字符串中搜索第一个匹配的值,找到就返回Match对象,否则返回None,语法如下:
re.search(pattern, string, [flags])
import re
pattern = r'py\w+'
string = 'python is PYTHON'
match = re.search(pattern, string, re.I) # re.I表示不区分大小写
print(match)
string = "这是python"
match = re.search(pattern, string, re.I)
print(match)
从运行结果可以看出,这个方法不仅仅在字符串的起始位置搜索,其他位置有符合的匹配也可以。
3. 使用findall()方法进行匹配
findall()方法用于在整个字符串中搜索所有符合正则表达式的字符串,并以列表的形式返回。查找不到就返回空列表。
re.findall(pattern, string, [flags])
import re
pattern = r'py\w+'
string = 'python is PYTHON'
match = re.findall(pattern, string, re.I) # re.I表示不区分大小写
print(match)
string = "这是python"
match = re.findall(pattern, string, re.I)
print(match)
4. 替换字符串
sub方法用于实现字符串替换。在爬虫中很少会用到。等遇到后和大家分享。
5. 用split()方法分割字符串
import re
pattern = r'[?|&]'
url = 'https://search.bilibili.com/live?keyword=IT蜗壳'
result = re.split(pattern, url)
print(result)
这里用?将url分割了两部分
你的问题是啥
bfadsnkfadsfmsadf
6666
加油啊
有人吗有人吗
卧槽,nb
sbycs
准备好了么
还有五分钟
爬取如下地址: url = 'http://gaosan.com/gaokao/265440.html数据,获取前100名学校的数据,如下图所示:

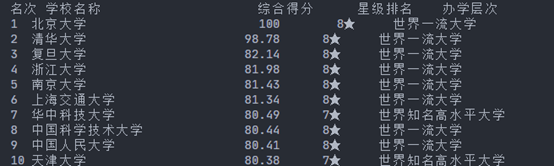

要求:
1. 设计函数,获取数据以后存入csv格式的文件,文件命名规则如下:学号.csv;
2. 设计函数,计算这前100名学校综合得分平均值,最大值,最小值及中位值,并把结果写入到”学号result.txt”文件中;
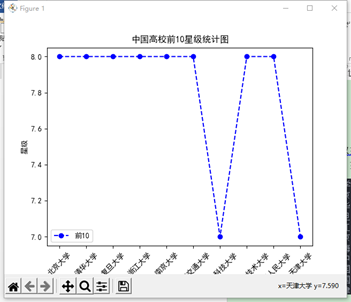
3. 以前10名大学星级数据折线图:
(1) x轴为大学名称,45°标在x轴上;
(2) y轴为星级,坐标轴数值系统自动分配;
(3) 折线图的标题设为“中国高校前10星级分统计图”
(4) 线形为“--”
(5) 线宽“2.5”
(6) 线色为蓝色;
(7) 标注图例;
(8) 线上标注圆形数据点;
(9) 保存绘图文件"学号.png"
4. 提交程序运行小视频;
5. 以文件形式提交源程序代码;
6. 提交运行截图;
7. 提交csv,png及text文件;
链接:https://pan.baidu.com/s/1a-cAtS8YUvsJe1skyCUQUA
提取码:g5gh
复制这段内容后打开百度网盘手机App,操作更方便哦
关于PyInstaller库,以下能够为其指定图标文件的选项是:
def foo(s):
if s == "":
return s
else:
return foo(s[1:]) + s[0]
print foo("Happy New Year")
这题运行结果是多少
有人在吗 大题目一点都不会 要死了
plt.rcParams['font.sans-serif']=['SimHei']
有无画折现图选手
import matplotlib.pyplot as plt
from matplotlib.pyplot import MultipleLocator
from matplotlib.pyplot import savefig
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False
squares=[100,98.78,82.14,81.98,81.43,81.34,80.49,80.44,80.41,80.38]
x=['北京大学','清华大学','复旦大学','浙江大学','南京大学','上海交通大学','华中科技大学','中国科学技术大学','中国人民大学','天津大学']
plt.xticks(rotation=45)
plt.title('中国高校前10得分统计图')
plt.plot(x,squares, color='blue',markerfacecolor='blue',marker='o',linestyle='--',linewidth=2.5)
plt.ylabel('综合得分',fontsize=17)
plt.ylim(79,101)
y_major_locator=MultipleLocator(5)
ax=plt.gca()
ax.yaxis.set_major_locator(y_major_locator)
plt.savefig('19131021.png')
plt.show()
plt.xticks(x, names, rotation=45)
plt.xticks(rotation=45)
x=[]
y=[]
s=0
for i in datalist :
if(s>0 and s<11):
x.append(str(i[1]))
y.append(str(i[3]))
s=s+1
有人吗有人吗