用python的pdfplumber包提取pdf文档中的表格,表格不能准确提取,如何解决?
p= pdfplumber.open("E:\我的文档\公司年报\濮阳惠成:2017年年度报告.pdf" )
p0= p.pages[102]
im= p0.to_image()
im.reset().debug_tablefinder()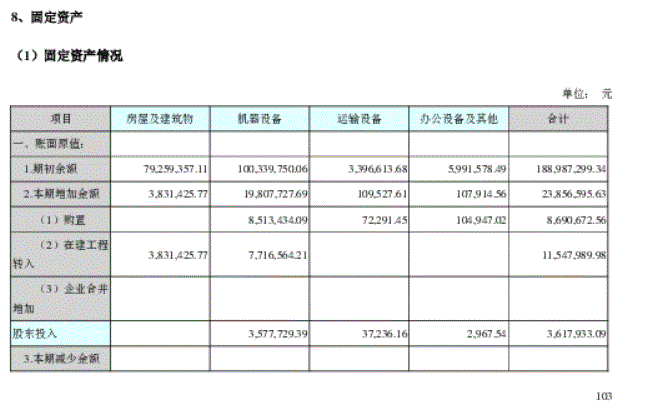

上图1是文档原文
图2是表格的切分,不能还原原始文档的表格。由于要处理的类似文档较多,希望能找到通用的解决办法。
谢谢!


黄老师您好:图2是原表,
图1是错误的分割-------把同一个单元格的内容分成了两行,这个该如何解决?
谢谢!
这个转换是会存在一定误差的,你可以做一个通用处理,比如出现空的单元格,可以与其他单元格合并处理
如果对你有帮助,可以点击我这个回答右上方的【采纳】按钮,给我个采纳吗,谢谢
大概逻辑是这样,详细示例代码自己百度一下,应该一大把的
for i in range(1, 10):
if cell(1, i) == '' and cell(1, i-1) == '':
# cell(1, i)合并cell(1, i-1)
pass上面示例是cell(1, i),1代表第一行,i代表第几列,然后同时判断自身和前面一个单元格是否为空,如果符合条件就合并处理,最后将所有邻近空的单元格合并为一个空的单元格。
您好,我是有问必答小助手,您的问题已经有小伙伴解答了,您看下是否解决,可以追评进行沟通哦~
如果有您比较满意的答案 / 帮您提供解决思路的答案,可以点击【采纳】按钮,给回答的小伙伴一些鼓励哦~~
ps:问答VIP仅需29元,即可享受5次/月 有问必答服务,了解详情>>>https://vip.csdn.net/askvip?utm_source=1146287632