初学者,请教一下 BeautifulSoup 的问题
我用的是python3.8。
这段代码成功运行了但是没有输出是为什么呢?救救孩子吧!!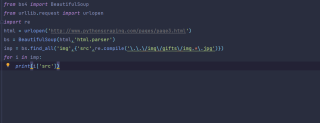


from bs4 import BeautifulSoup
from urllib.request import urlopen
import re
html = urlopen('http://www.pythonscraping.com/pages/page3.html')
bs = BeautifulSoup(html,'html.parser')
imp = bs.find_all('img')
for i in imp:
print(i['src'])
这样写
看一下节点有没有获取到 你把代码复制上来我帮你测。
运行了但是没有输出可能是你正则表达式过滤后没有数据了,所以没有输出东西,
您好,我是有问必答小助手,您的问题已经有小伙伴解答了,您看下是否解决,可以追评进行沟通哦~
如果有您比较满意的答案 / 帮您提供解决思路的答案,可以点击【采纳】按钮,给回答的小伙伴一些鼓励哦~~
ps:问答VIP仅需29元,即可享受5次/月 有问必答服务,了解详情>>>https://vip.csdn.net/askvip?utm_source=1146287632