Python中read方法读取文件时设置多层索引出现问题
一个非常简单的Excel测试文件,在用read语句读取之后,index_col参数设定为某一列时,一切正常(如图)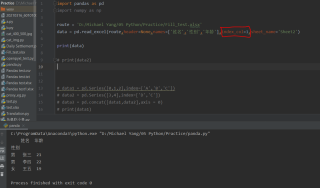
但是,当保持所有其他代码不变,尝试通过将列表传入index_col参数设置多层索引时,遇到报错(如下图)
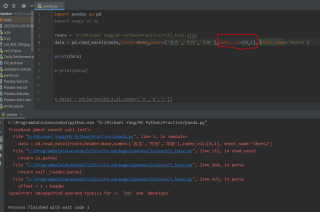
pandas.read_excel()中的index_col参数是指定列为索引列,默认为None,也就是索引为0的列用作DataFrame的行标签。当它为整数时,指定第几列为索引列,当它是一个整数列表时,就选择列表中的这些列作为索引列。运行没有问题,检查原表中数据有无改动,是不是无表头数据 。估计是你安装的pandas版本问题。测试运行正常的pandas版本号为1.1.3
年龄
姓名 性别
张三 男 21
李四 男 22
王五 女 19如解答对你有帮助,请点击一下采纳。
说明这个参数不知道列表格式,只支持int类型
如果对你有帮助,可以点击我这个回答右上方的【采纳】按钮,给我个采纳吗,谢谢
您好,我是有问必答小助手,您的问题已经有小伙伴解答了,您看下是否解决,可以追评进行沟通哦~
如果有您比较满意的答案 / 帮您提供解决思路的答案,可以点击【采纳】按钮,给回答的小伙伴一些鼓励哦~~
ps:问答VIP仅需29元,即可享受5次/月 有问必答服务,了解详情>>>https://vip.csdn.net/askvip?utm_source=1146287632