用python读取txt并删除某列
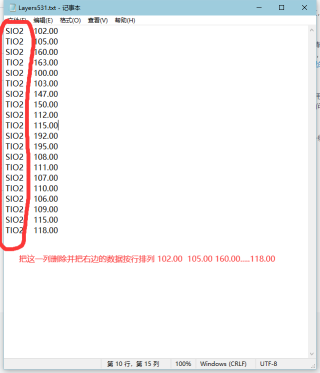

求代码
import codecs
f = codecs.open('data.txt', mode='r', encoding='utf-8') # 打开txt文件,以‘utf-8’编码读取
line = f.readline() # 以行的形式进行读取文件
list1 = []
while line:
a = line.split()
b = a[1:2] # 这是选取需要读取的位数
list1.append(b) # 将其添加在列表之中
line = f.readline()
f.close()
list1.sort()
for i in list1:
print(i)代码如上,万望采纳。
您好,我是有问必答小助手,您的问题已经有小伙伴解答了,您看下是否解决,可以追评进行沟通哦~
如果有您比较满意的答案 / 帮您提供解决思路的答案,可以点击【采纳】按钮,给回答的小伙伴一些鼓励哦~~
ps:问答VIP仅需29元,即可享受5次/月 有问必答服务,了解详情>>>https://vip.csdn.net/askvip?utm_source=1146287632
import codecs
# 使用说明:
# 1、脚本所在目录需要新建new和old目录
# 2、源文件放在old目录下,执行脚本后,新的文件自动保存在new目录下
# 读取txt中需要的列值
def read_data(file):
data = list()
with codecs.open(file, 'r', encoding='utf-8') as f:
for line in f:
a = line.split()
b = a[1:2] # 读取的列数
data.append(b)
return data
# 将内容写入新文件
def write_data(data, file):
with codecs.open(file, 'w', encoding='utf-8') as f:
new_data = ""
for i in data:
new_data += " " + i[0]
f.write(new_data)
if __name__ == "__main__":
for i in range(1, 2001):
old_file = "old/Layers{}.txt".format(i)
new_file = "new/Layers{}.txt".format(i)
try:
data = read_data(old_file) # 读取内容
write_data(data, new_file) # 内容写入新文件
except:
pass使用说明: 1、脚本所在目录需要新建new和old目录 2、源文件放在old目录下,执行脚本后,新的文件自动保存在new目录下
直接删除做不到,可以这样,首先文件中格式写成这样

import pandas as pd
df = pd.read_csv("C:/Users/Lenovo/Desktop/1.txt")
df_new = df[['new']]
df_new.to_csv('C:/Users/Lenovo/Desktop/2.txt', header=True, index=None)运行后2.txt文件中:

