关于matlab中函数或变量 'y' 无法识别的问题
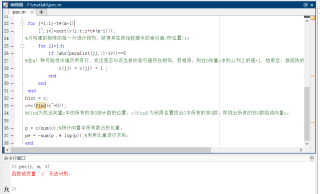
function [pe ,hist] = pec(y,m,t)
% Calculate the permutation entropy
% Input: y: time series;
% m: order of permuation entropy 嵌入维数
% t: delay time of permuation entropy,延迟时间
% Output:
% pe: permuation entropy
% hist: the histogram for the order distribution
ly = length(y);
permlist = perms(1:m);
% perms函数可将某个向量生成一个矩阵,利用该向量的内容进行排列。比如本例中的1,2,3,4,...,(m-1),m这个向量。其无序排列的结果有m!种,将m!种排到一个矩阵,为m!*m矩阵
[h,l]=size(permlist);
c(1:length(permlist))=0;
%生成一个1*m!的均为0的向量。其实用zeros更好。c=zeros(1,length(permlist))
for j=1:ly-t*(m-1)
[~,iv]=sort(y(j:t:j+t*(m-1)));
%对构建的矩阵的每一行进行排列,获得其在原始数据中的索引值(即位置)iv
for jj=1:h
if (abs(permlist(jj,:)-iv))==0
%在m!种可能性中遍历所有行,找出是否与该当前的索引值存在相同,若相同,则在0向量c中的jj列上的值+1,结束后,换矩阵的另一行继续找相同的索引值。总计K行。
c(jj) = c(jj) + 1 ;
end
end
end
hist = c;
c=c(find(c~=0));
%find为找出向量c中的所有的非0统计数的位置。c(find)为利用位置找出C中所有的非0数。即挑出所有的非0数组成向量c。
p = c/sum(c);%统计向量中所有数占的比重。
pe = -sum(p .* log(p));%利用比重进行求和。
end
 有没有大佬回答一下,这是咋回事呀
有没有大佬回答一下,这是咋回事呀
你好,我是有问必答小助手,非常抱歉,本次您提出的有问必答问题,技术专家团超时未为您做出解答
本次提问扣除的有问必答次数,将会以问答VIP体验卡(1次有问必答机会、商城购买实体图书享受95折优惠)的形式为您补发到账户。
因为有问必答VIP体验卡有效期仅有1天,您在需要使用的时候【私信】联系我,我会为您补发。