Redis操作大key为什么会导致CPU升高,原理是什么?
Redis操作大key为什么会导致CPU升高,原理是什么?
数据量大,CPU要计算,处理,存储,肯定会升高。
当单key过大时,每一次访问都会造成redis阻塞,其他请求只能等待了,如果应用中设置了1秒超时等,那么用户就会得到一个错误信息。最后删除的时候也会造成redis阻塞,到时候内存中数据量过大,就会造成CPU温度升高。
我想问的CPU的软中断和上下文切换也会升高,具体底层是怎么样的导致CPU升高
1.什么是大key
Redis是一个key,value数据库。大key即Key存储的value非常大。当value为哈希表、集合、有序集或链表时指存储的元素过多(上万)。当value为字符串时一般指单个字符串超过1M。也包括Key数量极多的情况,例如key数量达到千万上亿的规模。
2.大key导致性能下降的原因
大key导致性能下降redis的结构相关,首先redis是一个key,value数据库,其次redis使用了单线程模型来处理任务。
2.1 redis的key、value存储结构
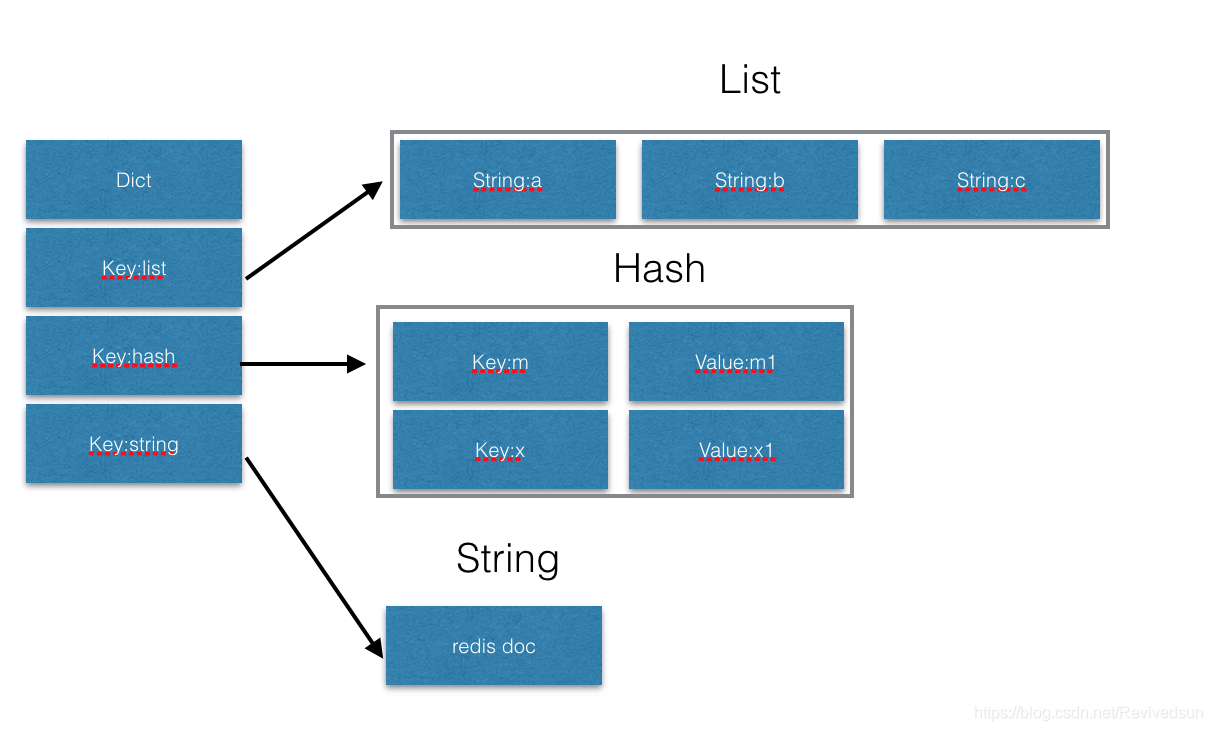
redis是一个key,value数据库。内部通过dict数据结构保存key, value。如下图所示,key也是会占用空间。因此大量的key也会造成空间大量消耗。
3 大key的几种处理方式
通过2.1与2.2可知,处理大key耗时过多,会导致其它请求响应时间变长以及空间消耗过大。而大key的几种场景及处理方式可以分为如下几种。
3.1 哈希、集合、有序集合、链表中元素数量过多
如果单个集合中元素过多,那么我们将其拆分成多个小集合,然后再通过路由算法找到具体的子集即可。以哈希表为例,将大哈希表拆分为5个小哈希表。那么拆分后,先计算key的哈希值,利用hash(key)%5得到key到底落在哪个哈希表上即可。同理集合,有序集合,链表的处理方式也是一样。但如果某些场景下拆分后,要保证按照元素存储顺序获取,就需要附加一些额外属性来实现。但总体思路就是拆分,但实际操作还要考虑具体的业务场景。
3.2 存储的key过多
key也是会占据空间。如果存储一个用户信息通过string去存结构如下:
user.name = michael;
user.age=19
user.id=111
- 1
- 2
- 3
由于存储的信息都属于一个用户。因此为了减少前缀占用的空间可以通过哈希表存储。
key=111
value= hashMap
Key:name,value michael
Key:age,value 19
- 1
- 2
- 3
- 4
修改后,不再重复存储key中公共前缀,降低空间浪费。因此这种处理方法依然是拆分,减少公共数据,降低存储空间浪费。当然最终的使用和实际的业务场景相关。
3.3 字符串类型单个key存储的value过大
思路依然是拆分,然后通过批量获取命令获取。value过大进行拆分其目的是降低单次操作的对服务端带来压力,避免value过大对IO产生的影响。
3.4.bitmap/布隆过滤器过大时的处理
bitmap/布隆过滤器处理思路依然是拆分。一个大的bitmap拆分后需要注意,利用多个hash函数计算key的哈希值后,最终key应该都落在一个bitmap上。如果落在拆分后的多个bitmap上,获取一个key的值将会产生多次查询,那么将大大降低查询的效率。
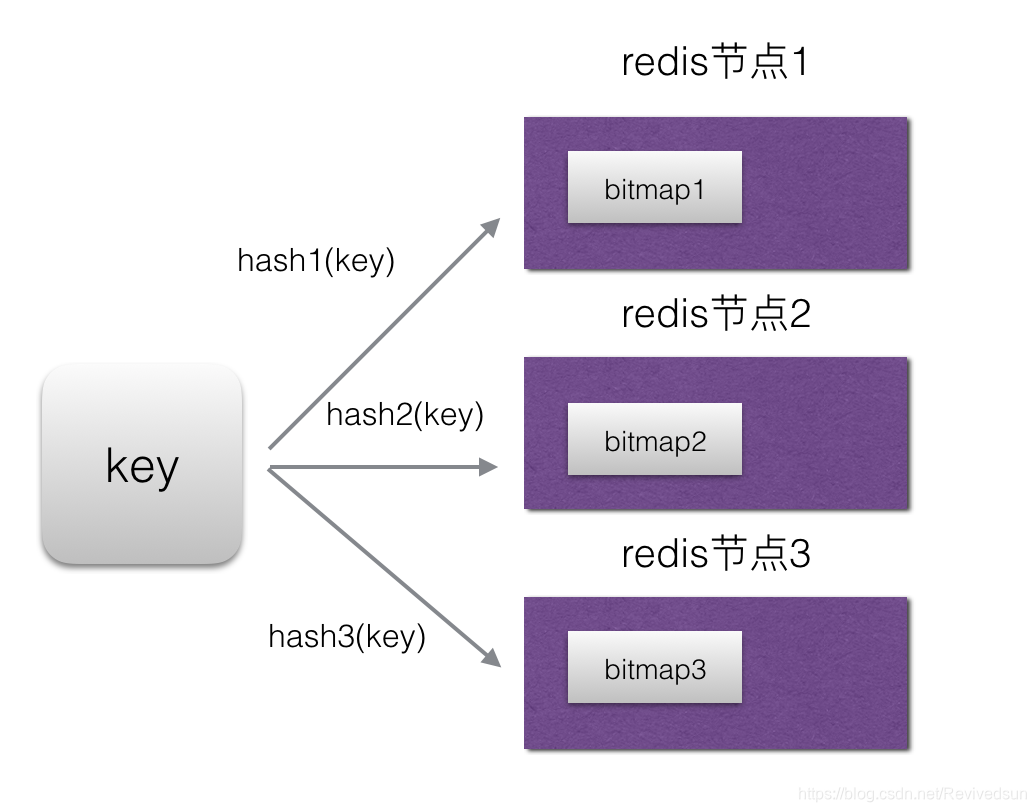
要保证多个hash函数计算后路由到同一个节点,那么才能提高查询效率。否则会向上图所示,拆分后要查询多个节点才能拿到结果。拆分后bitmap虽然变小,当作为布隆过滤器使用时,其误判概率并不会随之增大。因为误判是概率是与哈希函数个数,集合元素数量及bitmap大小相关。
您好,我是有问必答小助手,您的问题已经有小伙伴解答了,您看下是否解决,可以追评进行沟通哦~
如果有您比较满意的答案 / 帮您提供解决思路的答案,可以点击【采纳】按钮,给回答的小伙伴一些鼓励哦~~
ps:问答VIP仅需29元,即可享受5次/月 有问必答服务,了解详情>>>https://vip.csdn.net/askvip?utm_source=1146287632