python爬取web网页表格数据时,如何获取对应表头?
目前公司有一web ERP系统(特定APP扫码登录)需要每天导数据(十多种类型表格,每种类型表格有表头20-30个,数据内容通过外部加载),比较麻烦,想通过python自动化,但是在爬取过程中爬取后的数据输出导表格后发现表头全是英文,如何匹配对应中文?下面是部分截图:
其中一个表格“检查” html部分:
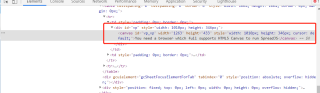
其中一个表格需求的数据:
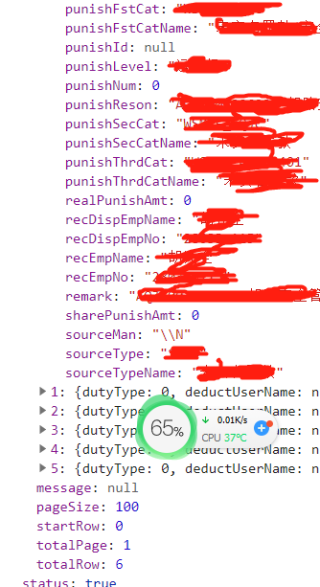
其中一个表头的中文:
![]()
开发者模式下搜索表头字段结果:

请各位大神支招如何快速提取中文表头,在哪里提取,怎么提取,谢谢(不方便发url)!
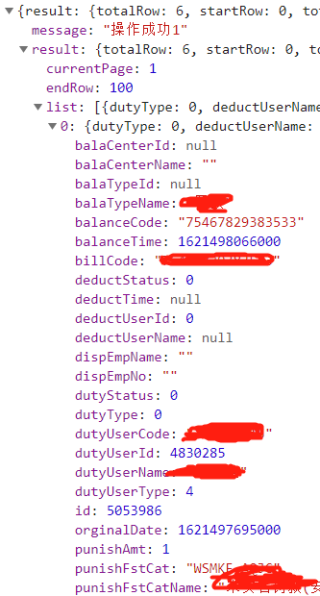
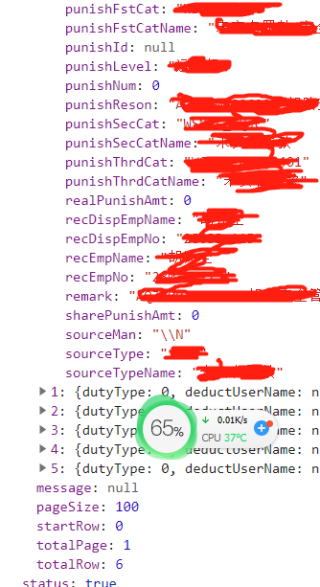
获取数据的json部分
是不是人家网站里有另外的文件里面有英文对应的中文?
还是没太懂。。。从这json里面拿出来的键名,也就是你要的表头肯定是英文啊。你想直接要中文?所以在F12里面查中文表头?
就我所知道的,页面表格的渲染方式:前端写好表头,从后端接口中获取数据json,一个一个对应。所以我认为你还是得自己写一个表头,一个一个对应
数据给个全版,信息可以打码
试一下使用requests库和BeautifulSoup库
https://wwa.lanzoui.com/izHRapha6oh
自己去下载吧,我爬过一个和你类似的。你网址改下,然后那个要查询的内容改下基本上就可以了
