如何用python把位图(模糊图)转换成文字
图片如下
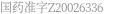
我要具体的代码,麻烦了!
import base64
import requests
def ocr(_fp):
#注:_fp为rb模式的文件
img="data:image/png;base64,"+base64.b64encode(_fp.read()).decode()
r=requests.post("https://ai.baidu.com/aidemo",
data={
"image":img,
"image_url":url,
"type":"commontext",
"detect_direction":False
},
headers=__HEADER
)
return "\n".join([x["words"] for x in r.json()["data"]["words_result"]])先装requests
>>> from PIL import Image
>>> import numpy as np
>>> import matplotlib.pyplot as plt
>>> im = np.array(Image.open(r'd:\1621324257136.jpg'))
>>> plt.imshow(im)
<matplotlib.image.AxesImage object at 0x000001D8168EB148>
>>> plt.savefig(r'd:\demo.svg')
这个要用到图像识别文字的库Tesseract吧
###安装tesseract-ocr引擎
brew install tesseract然后我们通过tesseract -v看一下是否安装成成功
tesseract 3.05.01leptonica-1.75.0libjpeg 9b : libpng 1.6.34 : libtiff 4.0.9 : zlib 1.2.11
这时候我们运行上面代码会出现乱码
这是因为tesseract默认只有语言包中没有中文包,如下图:
###安装tesseract-ocr语言包
我们去GitHub下载我们需要的语言包,这里我只下载了chi_tra.traineddata和chi_sim.traineddata
github:tesseract-ocr/tessdata
然后放到/usr/local/Cellar/tesseract/3.05.01/share/tessdata路径下面。
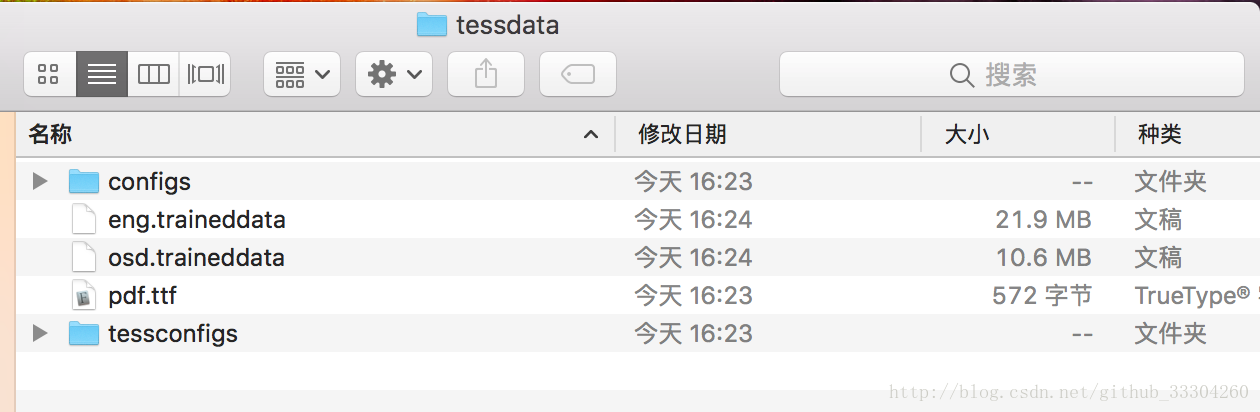
可以通过tesseract --list-langs查看本地语言包:
可以通过tesseract --help-psm 查看psm
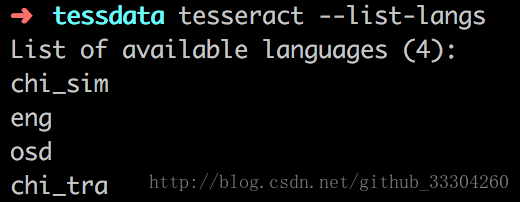
0:定向脚本监测(OSD)1: 使用OSD自动分页2 :自动分页,但是不使用OSD或OCR(Optical Character Recognition,光学字符识别)3 :全自动分页,但是没有使用OSD(默认)4 :假设可变大小的一个文本列。5 :假设垂直对齐文本的单个统一块。6 :假设一个统一的文本块。7 :将图像视为单个文本行。8 :将图像视为单个词。9 :将图像视为圆中的单个词。10 :将图像视为单个字符。
为什么这里要强调语言包和psm,因为我们在使用中会用到,
比如多个语言包组合并且视为统一的文本块将使用如下参数:
pytesseract.image_to_string(image,lang="chi_sim+eng",config="-psm 6")
这里我们通过+来合并使用多个语言包。
接下来我们看一下配置好一切的正确结果。
import pytesseractfrom PIL import Imageimage = Image.open("../pic/c.png")code = pytesseract.image_to_string(image,lang="chi_sim",config="-psm 6")print(code)