Python如何提取PDF图片中的数据
如图,请问有那位大神可以帮忙看一下,下面的这张图,如果想提取其中的38 38 40 31 41 47 29 38 47 38 54 37 19几个数字,该如何设置extract_table中的table_setting 的参数,或者有别的什么安装包可以解决吗?感激不尽!
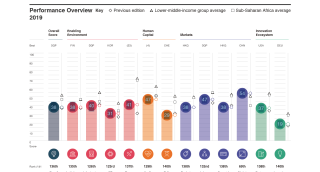
用ocr图像识别。百度阿里都有接口。
您好,我是有问必答小助手,您的问题已经有小伙伴解答了,您看下是否解决,可以追评进行沟通哦~
如果有您比较满意的答案 / 帮您提供解决思路的答案,可以点击【采纳】按钮,给回答的小伙伴一些鼓励哦~~
ps:问答VIP仅需29元,即可享受5次/月 有问必答服务,了解详情>>>https://vip.csdn.net/askvip?utm_source=1146287632