好像和jieba有关,是Python的内容
3.用汉语输入两句话,统计其中出现各种词语的次数。 (给出源程序代码并截图运行结果)
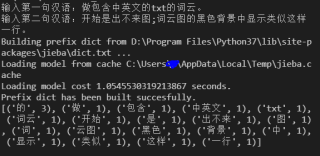
用jieba进行分词,用collections的Counter进行计数,代码及运行结果:
import jieba
import string
from collections import Counter
inp1=input('输入第一句汉语:')
inp2 = input('输入第二句汉语:')
inp=inp1+inp2
all_punc = string.punctuation+',。、【 】 “”:;()《》‘’{}?!⑦()、%^>℃:.”“^-——=&#@¥'
words=jieba.cut(inp)
word_num=Counter([w for w in words if w not in all_punc])
result =sorted(word_num.items(), key=lambda x: x[1], reverse=True)
print(result)
您好,我是有问必答小助手,您的问题已经有小伙伴解答了,您看下是否解决,可以追评进行沟通哦~
如果有您比较满意的答案 / 帮您提供解决思路的答案,可以点击【采纳】按钮,给回答的小伙伴一些鼓励哦~~
ps:问答VIP仅需29元,即可享受5次/月 有问必答服务,了解详情>>>https://vip.csdn.net/askvip?utm_source=1146287632