数据的合并去重,怎样提高效率?
python+sqlserver2008R2+dbutils+threadpoolexecutor
以上是目前的技术栈。
问题描述如下图:
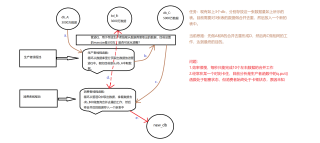
:
针对数据合并去重这个问题,需要考虑以下几点来提高效率:
数据格式化:将需要合并去重的数据进行格式化,使其符合统一的数据格式,从而方便进行合并去重操作。
数据索引优化:创建合适的索引,可以显著提高数据的查询和匹配效率。
批量操作:通过批量处理操作(如批量插入、批量删除等),可以减少操作数据库的次数,从而提高效率。
多线程处理:可以采用多线程的方式对数据进行合并去重操作,充分利用计算机的多核处理能力,加速处理速度。
SQL语句优化:合理的SQL语句可以避免多余的计算和数据 I/O 操作,从而提高效率。
具体到你的技术栈,可以根据实际情况选择合适的方式进行优化,例如通过在Python中利用dbutils库对数据进行操作,采用threadpoolexecutor提高并发处理能力等等。同时,需要根据具体业务场景和数据量大小综合考虑,权衡各种因素以实现最优的效果。