response内容没有正常打印,页面出现'啥都没有'字样
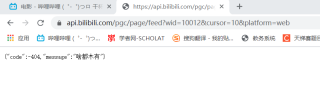

我想爬取这个网页前200的电影信息,但出现问题。这个网页https://api.bilibili.com/pgc/page/feed?wid=10012&cursor=10&platform=web在cursor值为0-9的时候都正常显示,到cursor值10以上network的response里有内容,但把网址贴到浏览器只显示'啥都没有'。
应该是你速度设置的不对,然后被系统探测到你是机器人流量很大,然后IP被限制了。估计会被限制1天。
应该是b站的反爬虫机制,一次最多爬取一定的数量,超过就不行了。
可以参考这个up的教程,有教学和源码python六步爬取B站电影信息,你的名字果然最火......_哔哩哔哩 (゜-゜)つロ 干杯~-bilibili
请求接口的页面地址是哪个页面?
应该是超过10页后,需要一些验证的cookie信息,request对象要附带上对应cookie信息,需要研究请求的页面附带了哪些cookie,要附加上

我用POSTMan 做了一下,确实是可以传到参数10
https://api.bilibili.com/pgc/page/feed?wid=10012&cursor=10platform=web
你用这个链接跑。
import requests
import json
import pandas as pd
lists = []
index = []
count = 0
# 下载网页
for i in range(10): # 链接通过往下滑加载页面发现网址规律
url = 'https://api.bilibili.com/pgc/page/feed?wid=10012&cursor=' + str(i) + '&platform=web'
# 发送http get请求
response = requests.get(url).text
content = json.loads(response)
for i in range(len(content['result']['modules'])):
list = []
list.append(content['result']['modules'][i]['items'][0]['title'])
list.append(content['result']['modules'][i]['items'][0]['desc'])
list.append(content['result']['modules'][i]['items'][0]['aid'])
list.append(content['result']['modules'][i]['items'][0]['cid'])
lists.append(list)
count+=1
index.append(str(count))
print('爬取成功')
df = pd.DataFrame(lists,columns=['电影名', '介绍', 'aid', 'cid'],index=index)
df.to_csv(r"b站电影推荐.csv",encoding='utf_8_sig') # 解码
您好,我是有问必答小助手,您的问题已经有小伙伴解答了,您看下是否解决,可以追评进行沟通哦~
如果有您比较满意的答案 / 帮您提供解决思路的答案,可以点击【采纳】按钮,给回答的小伙伴一些鼓励哦~~
ps:问答VIP仅需29元,即可享受5次/月 有问必答服务,了解详情>>>https://vip.csdn.net/askvip?utm_source=1146287632