利用python将一张总表按指定列进行分类并生成多张表,指定格式
我是一个小白,因工作需要,需要提高效率,需要指定格式,拆分出多张表,现利用下列代码能够实现表格拆分。还有三个功能没有实现,求各位大神帮忙解决下。
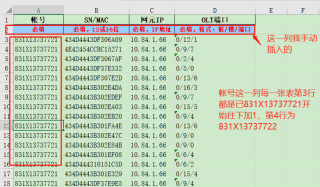
1、帐号这一列导出来每一张表格要以“831X13737721”这个帐号为基础,每行加1
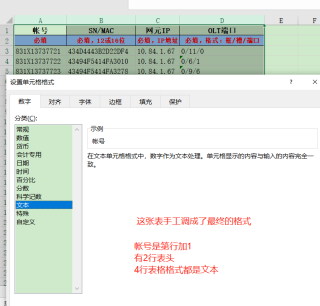
2、导出的表头要2行,第二列表头分别为:必填|必填,12或16位|必填,IP地址|必填,格式:框/槽/端口
3、导出的格式要为文本格式
下面是我写的代码
import pandas as pd
df = pd.read_excel("D:/python3/3605.xlsx")#读取文件
df['OLT端口'] = df["框号"].map(str) + "/" + df["槽号"].map(str) + "/" + df["端口号"].map(str)
df['帐号'] = "831X13737721"
df1 = df.iloc[:,[31,20,1,30]]
products = df1['网元IP'].drop_duplicates() #drop_duplicates:删除重复值,获取唯一值
for i in products:
df1[df['网元IP'] == i].to_excel('D:/python3/' + i + '.xlsx', sheet_name='IPTV业务信息表', index=0)
试试这样:
import pandas as pd
df = pd.read_excel("3605.xlsx")#读取文件
#df['OLT端口'] = df["框号"].map(str) + "/" + df["槽号"].map(str) + "/" + df["端口号"].map(str)
#df['帐号'] = "861x21"
df1 = df.iloc[:,[0,1,2,3]]#选取所需的列
#print(df1)
products = df1['网元IP'].drop_duplicates() #drop_duplicates:删除重复值,获取唯一值
df2=pd.DataFrame([['必填', '必填', '必填', '必填']],columns=df1.columns)#根据需要修改插入的字段名
df2=df2.append(df1,ignore_index=True)#添加一行到数据框中用于分表输出
for i in products:
df2.loc[1:,'账号'] = [x[:-1]+str(j+1) for j, x in enumerate(df2.loc[1:,'账号'])]#改账号
df2[df2['网元IP'] == i].to_excel(i + '.xlsx', sheet_name='IPTV业务信息表', index=0)#写入excel.
我可以用c# 帮您写吗...一样的
https://docs.microsoft.com/zh-cn/office/open-xml/how-to-get-worksheet-information-from-a-package
怎么导出的单位格格式为文本格式