R语言Rwordseg包分词问题
hotel <- read.csv("D:/Download/评论.txt")
segmentCN (hotel)
edit(hotel)
segmentCN("D:/Download/评论.txt")前两行代码报错:Error in segmentCN(hotel) : Please input character!
第三行代码数据表
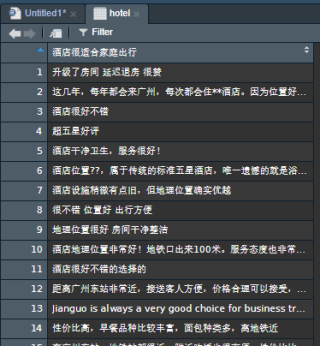
第四行代码结果:[1] "D" "Download" "评论" "txt"
问:为什么不能直接读取文件来分词?
segmentCN的用法是:segmentCN(strwords, analyzer = c("default", "hmm", "jiebaR", "fmm", "coreNLP"), nature = FALSE, nosymbol = TRUE, returnType = c("vector", "tm"), ...) ,第一个参数是中文字符串向量,你直接用数据框传入当然会报错。你在读取数据后,将数据转换成一个字符串向量即可。示例:
library(Rwordseg)
hotel <- read.csv("F:\\2021\\rtest\\meidi_jd.txt")
for (h in hotel){
ht=paste(h)
}
edit(hotel)
edit(ht)
segmentCN(ht)
segmentCN处理的是中文字符串,read.csv得到的是一个data.frame。
您好,我是有问必答小助手,您的问题已经有小伙伴解答了,您看下是否解决,可以追评进行沟通哦~
如果有您比较满意的答案 / 帮您提供解决思路的答案,可以点击【采纳】按钮,给回答的小伙伴一些鼓励哦~~
ps:问答VIP仅需29元,即可享受5次/月 有问必答服务,了解详情>>>https://vip.csdn.net/askvip?utm_source=1146287632
非常感谢您使用有问必答服务,为了后续更快速的帮您解决问题,现诚邀您参与有问必答体验反馈。您的建议将会运用到我们的产品优化中,希望能得到您的支持与协助!
速戳参与调研>>>https://t.csdnimg.cn/Kf0y