一个Python抓取网页数据的问题
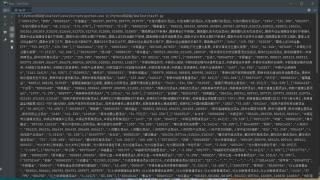
我想问问,像这种图片这种数据,怎么整理成数组?
我这边想以循环方式,再度抓取里面的详情页面内容,然后就生成一个相对应的SQL文件.
这个长的字符串, 前面后面各加一个[ ], 就成了'[[],[]]'' 这种格式, 可以用eval()再转换一下, 就成了[[],[]]
可以生成数组或者dataframe,dataframe可转成sql
(补充)
import numpy as np
st = "['1','2','3'],['A','B','C']" #假设数据样式
st_re = '['+st+']'
np.array(eval(st_re))
根据],[字符串进行分割,分割后是一条一条完整的记录,然后根据逗号分隔,变成一个一个字段的值。
对列表进行遍历,按键值对转换成字典,使用pandas转换成数据框,然后用df.to_sql()保存为sql。在获取网页数据的时候,要考虑到对后续数据格式处理,尽量使用字典键值对形式保存得到的数据,便于提取和数据预处理,如果静态网页上数据就是一个表格形式,首先尝试用pandas的 read_html()去获取,更方便更易于保存,省去很多后续处理的麻烦。
请采纳,谢谢!
给你说个最简单的,先保存为TXT文件(怎么保存为TXT文件网上一搜一大把),放到桌面,然后重命名文件格式为.sql
您好,我是有问必答小助手,你的问题已经有小伙伴为您解答了问题,您看下是否解决了您的问题,可以追评进行沟通哦~
如果有您比较满意的答案 / 帮您提供解决思路的答案,可以点击【采纳】按钮,给回答的小伙伴一些鼓励哦~~
ps:问答VIP仅需29元,即可享受5次/月 有问必答服务,了解详情>>>https://vip.csdn.net/askvip?utm_source=1146287632
非常感谢您使用有问必答服务,为了后续更快速的帮您解决问题,现诚邀您参与有问必答体验反馈。您的建议将会运用到我们的产品优化中,希望能得到您的支持与协助!
速戳参与调研>>>https://t.csdnimg.cn/Kf0y