求助?关于scrapy框架爬取不到网页源码的文本内容,以及url打开顺序问题?
初学爬虫,自己做练习。万分感谢大佬们解答。
先通过https://stockx.com/sneakers/中的源码获取该页面四十个款式的详情页,再对详情页进行请求。代码为测试阶段,暂时先选取第一个款式的链接进行测试。该链接为https://stockx.com/adidas-yeezy-boost-350-v2-core-black-red-2017。
问题:
(1)start_url里的链接是https://stockx.com/sneakers/,在parse函数中选取第一个款式的链接,通过yield回调到parse_detail函数。程序运行时,chromedriver直接就打开详情页链接而不是start里的链接(因为每次打开有一个地区语言的选择,暂时还不会scrapy的cookie导入),所以后面代码里只好在详情页的中加了一行地区选择语言确认按钮点击的代码。求大佬解答。
(2)在请求详情界面时,为获取详情页面中的货号,颜色,发售价等信息时,(代码中仅测试货号)使用response.xpath 和response.css都获取不到文本信息。求大佬解答。
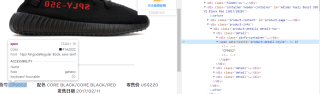
代码如下图
stock.py
import scrapy
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
class StockxSpider(scrapy.Spider):
name = 'stockx'
# allowed_domains = ['www.xxx.com']
start_urls = ['https://stockx.com/sneakers/']
urls = []#详情页链接
labels = []#款式
#浏览器初始化
def __init__(self):
self.option = Options()
self.option.add_experimental_option('excludeSwitches', ['enable-automation'])
self.bro = webdriver.Chrome(executable_path='./chromedriver.exe', options=self.option)
script = 'Object.defineProperty(navigator,"webdriver",{get:()=>undefined,});'
self.bro.execute_script(script)
#获取款式的详情页链接以及款式名
def parse(self, response):
div_list = response.xpath('//div[@class="browse-grid loading undefined"]/div[2]/div')
for div in div_list:
url = div.xpath('./div/a/@href').extract_first()
label = url[1:]
url = 'https://stockx.com/' + label
self.urls.append(url)
self.labels.append(label)
for url in self.urls:
break
yield scrapy.Request(url = url, callback = self.parse_detail)
#爬取货号
def parse_detail(self, response):
style = response.xpath('//div[@class="product-info"]/div/div[1]/span/text()').extract_first()
style1 = response.css('.product-info > div > div:nth-of-type(1) > span ::text').extract_first()
print(style)
print(style1)middlewares.py的主要代码部分
def process_response(self, request, response, spider):
bro = spider.bro
if request.url in spider.start_urls:#请求链接在初始链接池中
bro.get(request.url)
sleep(2)
bro.find_element_by_css_selector('.css-8c8ied').click()
page_text = bro.page_source
new_response = HtmlResponse(url=request.url, body=page_text, encoding='utf-8', request=request)
return new_response
elif request.url in spider.urls: #请求链接为详情页
bro.get(request.url)
sleep(2)
bro.find_element_by_css_selector('.css-8c8ied').click()#由于chrome直接打开详情页,就在这也加上了语言地区的确认按钮
page_text = bro.page_source
new_response = HtmlResponse(url=request.url, body=page_text, encoding='utf-8', request=request)
return new_response
else:
return response程序运行结果
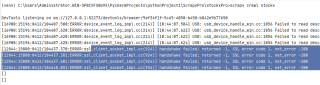
用response.xpath和css爬取货号得到的都是空值,xpath和css的路径应该没有写错,求大佬解答,万分感谢。
你先打印下response.text,看看得到的HTML有没有prodct-info类,或根据
//div[@class="product-info"]/div/div[1]/span/text()是否得到想要的值。
您好,我是有问必答小助手,你的问题已经有小伙伴为您解答了问题,您看下是否解决了您的问题,可以追评进行沟通哦~
如果有您比较满意的答案 / 帮您提供解决思路的答案,可以点击【采纳】按钮,给回答的小伙伴一些鼓励哦~~
ps:问答VIP仅需29元,即可享受5次/月 有问必答服务,了解详情>>>https://vip.csdn.net/askvip?utm_source=1146287632