如何对csv文件的的格式进行重新编写(要求用python,涉及循环)?
现在我有4000多个csv文件(把这四千多个文件转到其他目录的代码在下面给出)。
每个文件的格式如下图,我想把它们每个文件的第一和第二行删掉,现在我在下图已经完成,但在对第二行的名字进行修改时出现了问题,比如说我想把A列的日期改成英文date,B列的改成open,中文与英文一一对应,但在改完后的date却没和日期对应。
我想应该是我的excel文件的第二行只占一个格子,没有与第三行的日期,开盘等对应。现在想实现把这4000多个csv文件重新保存到另一个目录,但格式是按我上文说的格式。
我现在的思路:由于我的CSV文件是由excel打开的,如果把他们用文本编辑打开,是否能解决?

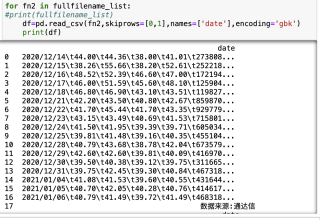
可能是调用read_csv方法的时候,没有指定分隔符。
用记事本打开看看,字段之间的分隔符是什么?空格还是Tab分隔?调用read_csv方法的时候,通过sep参数指定分隔符,然后再指定name。
提供下思路:
- 从数据看, 数据使用制表符, 也就是 \t分割, 用read_csv() , 设置sep='\t'(常用的分隔符 \s 表示空白字符,包括但不限于空格、回车(\r)、换行(\n)、tab或者叫水平制表符(\t) )
- 建议列名可以在读取文件后通过columns属性修改; 日期和data不对应的问题, 看是不是读取后有多的空白列(先拿几个文件试试)

这是excel文件的格式
在使用pandas.read_csv(),指定一下sep='\t',试一下看看。有关参数使用见博客:https://www.cnblogs.com/datablog/p/6127000.html
您好,我是有问必答小助手,你的问题已经有小伙伴为您解答了问题,您看下是否解决了您的问题,可以追评进行沟通哦~
如果有您比较满意的答案 / 帮您提供解决思路的答案,可以点击【采纳】按钮,给回答的小伙伴一些鼓励哦~~
ps:问答VIP仅需29元,即可享受5次/月 有问必答服务,了解详情>>>https://vip.csdn.net/askvip?utm_source=1146287632
1
已经解决,谢谢各位前辈