用selenium爬取淘宝多页数据时,只是重复打印一页
用selenium爬取淘宝多页数据时,只是重复打印一页
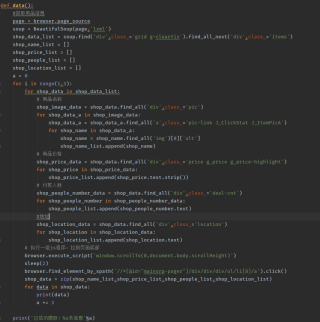
如果没看错的话,您在data函数中做了3次循环,是想爬前三页的数据吗?
如果是的话,问题就出在soup上,您的soup是第一页的内容,不管循环多少次,都是在对第一页进行操作
您需要将page_source中的url换成您想爬的网页的对应的url
您可以像这样
if __name__ == '__main__':
urls = {
'https://s.taobao.com/search?q=%E6%B0%B4%E6%9D%AF&imgfile=&js=1&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20210413&ie=utf8',
'https://s.taobao.com/search?q=%E6%B0%B4%E6%9D%AF&imgfile=&js=1&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20210413&ie=utf8&bcoffset=3&ntoffset=3&p4ppushleft=1%2C48&s=44',
'https://s.taobao.com/search?q=%E6%B0%B4%E6%9D%AF&imgfile=&js=1&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20210413&ie=utf8&bcoffset=0&ntoffset=6&p4ppushleft=1%2C48&s=88'}
for url in urls:
browser.get(url)
data()
from time import sleep
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from bs4 import BeautifulSoup
def login_info():
#通过扫码的形式去登录淘宝账号
browser.find_element_by_xpath('//*[@id="login"]/div[1]/i').click()
sleep(5)
#点击淘宝首页
taobao_index = browser.find_element_by_xpath('//*[@id="J_SiteNavHome"]/div/a')
taobao_index.click()
sleep(1)
def search_product():
# 标签定位
search_input = browser.find_element_by_id('q')
# 标签交互
search_input.send_keys('手机')
# 执行一组js程序,拉到页面底部
browser.execute_script('window.scrollTo(0,document.body.scrollHeight)')
sleep(2)
# 点击搜索按钮
btn = browser.find_element_by_css_selector('.btn-search')
btn.click()
def data():
#获取商品信息
page = browser.page_source
soup = BeautifulSoup(page,'lxml')
shop_data_list = soup.find('div',class_='grid g-clearfix').find_all_next('div',class_='items')
shop_name_list = []
shop_price_list = []
shop_people_list = []
shop_location_list = []
a = 0
for i in range(1,3):
browser.find_element_by_xpath('//*[@id="mainsrp-pager"]/div/div/div/ul/li[8]/a').click()
for shop_data in shop_data_list:
# 商品名称
shop_image_data = shop_data.find_all('div',class_='pic')
for shop_data_a in shop_image_data:
shop_data_a = shop_data_a.find_all('a',class_='pic-link J_ClickStat J_ItemPicA')
for shop_name in shop_data_a:
shop_name = shop_name.find_all('img')[0]['alt']
shop_name_list.append(shop_name)
# 商品价格
shop_price_data = shop_data.find_all('div',class_='price g_price g_price-highlight')
for shop_price in shop_price_data:
shop_price_list.append(shop_price.text.strip())
# 付款人数
shop_people_number_data = shop_data.find_all('div',class_='deal-cnt')
for shop_people_number in shop_people_number_data:
shop_people_list.append(shop_people_number.text)
#地址
shop_location_data = shop_data.find_all('div',class_='location')
for shop_location in shop_location_data:
shop_location_list.append(shop_location.text)
# 执行一组js程序,拉到页面底部
browser.execute_script('window.scrollTo(0,document.body.scrollHeight)')
sleep(2)
shop_data = zip(shop_name_list,shop_price_list,shop_people_list,shop_location_list)
for data in shop_data:
print(data)
a += 1
print('已成功爬取:%s条信息'%a)
if __name__ == '__main__':
browser = webdriver.Chrome(executable_path='./chromedriver')
taobao_index = browser.get('https://login.taobao.com/member/login.jhtml')
# 窗口最大化
browser.maximize_window()
wait = WebDriverWait(browser, 10)
login_info()
search_product()
data()
from time import sleep
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from bs4 import BeautifulSoup
def login_info():
#通过扫码的形式去登录淘宝账号
browser.find_element_by_xpath('//*[@id="login"]/div[1]/i').click()
sleep(5)
#点击淘宝首页
taobao_index = browser.find_element_by_xpath('//*[@id="J_SiteNavHome"]/div/a')
taobao_index.click()
sleep(1)
def search_product(value):
# 标签定位
search_input = browser.find_element_by_id('q')
# 标签交互
search_input.send_keys(value)
# 执行一组js程序,拉到页面底部
browser.execute_script('window.scrollTo(0,document.body.scrollHeight)')
sleep(2)
# 点击搜索按钮
btn = browser.find_element_by_css_selector('.btn-search')
btn.click()
def data(value):
#获取商品信息
shop_name_list = []
shop_price_list = []
shop_people_list = []
shop_location_list = []
a = 0
b = 0
for i in range(1,3):
page = browser.page_source
soup = BeautifulSoup(page, 'lxml')
shop_data_list = soup.find('div', class_='grid g-clearfix').find_all_next('div', class_='items')
for shop_data in shop_data_list:
# 商品名称
shop_image_data = shop_data.find_all('div',class_='pic')
for shop_data_a in shop_image_data:
shop_data_a = shop_data_a.find_all('a',class_='pic-link J_ClickStat J_ItemPicA')
for shop_name in shop_data_a:
shop_name = shop_name.find_all('img')[0]['alt']
shop_name_list.append(shop_name)
# 商品价格
shop_price_data = shop_data.find_all('div',class_='price g_price g_price-highlight')
for shop_price in shop_price_data:
shop_price_list.append(shop_price.text.strip())
# 付款人数
shop_people_number_data = shop_data.find_all('div',class_='deal-cnt')
for shop_people_number in shop_people_number_data:
shop_people_list.append(shop_people_number.text)
#地址
shop_location_data = shop_data.find_all('div',class_='location')
for shop_location in shop_location_data:
shop_location_list.append(shop_location.text)
# 执行一组js程序,拉到页面底部
browser.execute_script('window.scrollTo(0,document.body.scrollHeight)')
sleep(2)
shop_data = zip(shop_name_list,shop_price_list,shop_people_list,shop_location_list)
for data in shop_data:
print(data)
a += 1
browser.get(f"https://s.taobao.com/search?q={value}&s={b}")
b += 44
print('已成功爬取:%s条信息'%a)
if __name__ == '__main__':
browser = webdriver.Chrome(executable_path='./chromedriver')
taobao_index = browser.get('https://login.taobao.com/member/login.jhtml')
# 窗口最大化
browser.maximize_window()
wait = WebDriverWait(browser, 10)
login_info()
value = input("请输入你要查询的关键词:")
search_product(value)
data(value)
答主,但你的意思修改后还是不行,我要哭了