第五十行大家看看为啥报错啊,弄了好久了
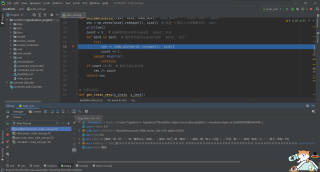
Traceback (most recent call last):
File "E:/python/spider/svm&lstm/svm/train_svm.py", line 130, in <module>
get_train_vecs(x_train, x_test) # 计算词向量并保存为train_vecs.npy,test_vecs.npy
File "E:/python/spider/svm&lstm/svm/train_svm.py", line 70, in get_train_vecs
train_vecs = np.concatenate([buildWordVector(z, n_dim, imdb_w2v) for z in x_train])
File "E:/python/spider/svm&lstm/svm/train_svm.py", line 70, in <listcomp>
train_vecs = np.concatenate([buildWordVector(z, n_dim, imdb_w2v) for z in x_train])
File "E:/python/spider/svm&lstm/svm/train_svm.py", line 49, in buildWordVector
t = imdb_w2v[word].reshape((1, size))
TypeError: 'Word2Vec' object is not subscriptable
直接原因是 imdb_w2v[word] 这里的 word 是 Word2Vec 类型对象,不能用来做 imdb_w2v 的切片脚标,检查下 imdb_w2v 的定义。
第50行的word是字符串类型,不能作为下标进行索引