关于hashMap和LinkedHashMap的查询速度问题
网上看了很多博客,关于hashMap和LinkHashMap的区别时候,基本上都说的是HashMap查询速度快,LinkedHashMap的查询速度慢,我自己测试了一下,代码如下:
结果不管我设置一次插入数值多少,写入的速度和读取的速度,都是LinkedHashMap吊打hashMap,有大佬来解释一下原因么?
public static void insertHashMapTest() throws InterruptedException {
int size=50000;
HashMap<String, Double> hashMap = new HashMap<>(size);
System.out.println("----开始测试hashMap---");
long hashMapStart = System.currentTimeMillis();
for(int i=0;i<size;i++){
hashMap.put(UUID.randomUUID().toString(),Math.random());
}
System.out.println("hashMap插入"+size+"条数据消耗时间为:"+(System.currentTimeMillis()-hashMapStart));
long hashMapcheck = System.currentTimeMillis();
Iterator<Map.Entry<String, Double>> iterator = hashMap.entrySet().iterator();
while (iterator.hasNext()){
System.out.print(iterator.next().getValue());
}
System.out.println("##");
System.out.println("hashMap遍历"+size+"条数据消耗时间为:"+(System.currentTimeMillis()-hashMapcheck));
//清空hashMap,避免影响内存
hashMap.clear();
//清除hashmap需要时间,此过程会影响linkedhashmap的速度,确保hashmap清理完毕再执行
Thread.sleep(3000);
System.out.println("hashMap长度:"+hashMap.size());
System.out.println("----开始测试linkHashMap---");
LinkedHashMap<String, Double> linkedHashMap = new LinkedHashMap<>(size);
long linkHashMapStart = System.currentTimeMillis();
for(int i=0;i<size;i++){
linkedHashMap.put(UUID.randomUUID().toString(),Math.random());
}
System.out.println("linkHashMap插入"+size+"条数据消耗时间为:"+(System.currentTimeMillis()-linkHashMapStart));
long linkHashMapcheck = System.currentTimeMillis();
Iterator<Map.Entry<String, Double>> iterator1 = linkedHashMap.entrySet().iterator();
while (iterator1.hasNext()){
System.out.print(iterator1.next().getValue());
}
System.out.println("##");
System.out.println("linkHashMap遍历"+size+"条数据消耗时间为:"+(System.currentTimeMillis()-linkHashMapcheck));
}
首先说一下你这个测试方法都是错的,什么叫查询?所谓的查询值得是从一堆数据中区检索到我想要的数据,而不是你所写的遍历,完全两码事。你查询总得有个被查的目标吧?遍历不等于查询!!!!!!!!
给你的代码改了一下,我查询的目标是中间的那个,也就是索引为size/2的:
public class QueryTest {
public static void main(String[] args) {
int size = 5000000;
HashMap<String, Double> hashMap = new HashMap<>(size);
System.out.println("----开始测试hashMap---");
long hashMapStart = System.currentTimeMillis();
for (int i = 0; i < size; i++) {
hashMap.put(i + "", Math.random());
}
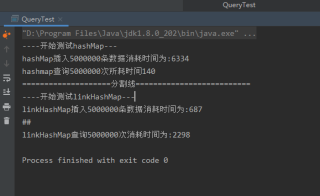
System.out.println("hashMap插入" + size + "条数据消耗时间为:" + (System.currentTimeMillis() - hashMapStart));
long hashMapcheck = System.currentTimeMillis();
for (int i = 0; i < size; i++) {
hashMap.get(size/2 + "");
}
System.out.println("hashmap查询" + size + "次所耗时间" + (System.currentTimeMillis() - hashMapcheck));
System.out.println("====================分割线==========================");
System.out.println("----开始测试linkHashMap---");
LinkedHashMap<String, Double> linkedHashMap = new LinkedHashMap<>(size);
long linkHashMapStart = System.currentTimeMillis();
for(int i=0;i<size;i++){
linkedHashMap.put(i+"",Math.random());
}
System.out.println("linkHashMap插入"+size+"条数据消耗时间为:"+(System.currentTimeMillis()-linkHashMapStart));
long linkHashMapcheck = System.currentTimeMillis();
for (int i = 0; i < size; i++) {
linkedHashMap.get(size/2 + "");
}
System.out.println("##");
System.out.println("linkHashMap查询"+size+"次消耗时间为:"+(System.currentTimeMillis()-linkHashMapcheck));
}
}
LinkedHashMap is among the four general-purpose implementation of the Map interface which is a subclass of the HashMap class meaning it inherits its features. Although it’s very similar to HashMap in terms of performance, except it maintains insertion order of keys, either in order in which the keys are inserted into the Map or the order in which the entries are accessed in the Map. It refines the contract of its parent class by guaranteeing the order in which iterators returns its elements. However, it requires more memory than a HashMap because it maintains a doubly-linked list in Java.
Read more: Difference Between HashMap and LinkedHashMap | Difference Between http://www.differencebetween.net/technology/software-technology/difference-between-hashmap-and-linkedhashmap/#ixzz6qlKxcKzp
你把测试hashMap和LinkedHashMap代码的顺序换一下式式。。。
UUID.randomUUID().toString()大多是这个在耗时,光一个随机uuid生成就七百左右了,单独测试的话差别是不大的,而且50000条也显示不出太大差别的,遍历的时候是输出耗时要比遍历多的多,而且遍历的时候LinkedHashMap是有优势的,使用迭代器遍历,都是有效的遍历,每次next都是能直接获取的,HashMap是要进行无效的遍历,因为填充因子的原因
1