MapReduce将本地数据读入数据库报错 java.io.IOException
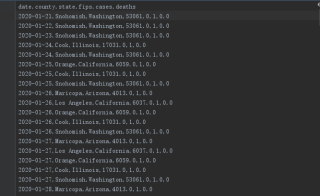
原始数据集
数据库建表存储结果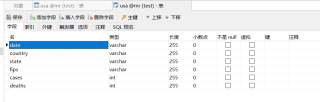

你要贴在代码框里,大家可以拷贝了运行,不然,纯人肉看,成本太高,大家就不愿意回答你的问题,你可能就要花很长的时间自己研究。
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapreduce.lib.db.DBWritable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
public class BeanSQL implements Writable, DBWritable {
private String date;
private String country;
private String state;
private String fips;
private int cases;
private int deaths;
@Override
public String toString() {
return "BeanSQL{" +
"date='" + date + '\'' +
", country='" + country + '\'' +
", state='" + state + '\'' +
", fips='" + fips + '\'' +
", cases=" + cases +
", deaths=" + deaths +
'}';
}
public void set(String date, String country, String state, String fips, int cases, int deaths) {
this.date = date;
this.country = country;
this.state = state;
this.fips = fips;
this.cases = cases;
this.deaths = deaths;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(date);
out.writeUTF(country);
out.writeUTF(state);
out.writeUTF(fips);
out.writeInt(cases);
out.writeInt(deaths);
}
@Override
public void readFields(DataInput in) throws IOException {
this.date = in.readUTF();
this.country = in.readUTF();
this.state = in.readUTF();
this.fips = in.readUTF();
this.cases = in.readInt();
this.deaths = in.readInt();
}
@Override
public void write(PreparedStatement statement) throws SQLException {
statement.setString(1,this.date);
statement.setString(2,this.country);
statement.setString(3,this.state);
statement.setString(4,this.fips);
statement.setInt(5,this.cases);
statement.setInt(6,this.deaths);
}
@Override
public void readFields(ResultSet resultSet) throws SQLException {
this.date = resultSet.getString(1);
this.country = resultSet.getString(2);
this.state = resultSet.getString(3);
this.fips = resultSet.getString(4);
this.cases = resultSet.getInt(5);
this.deaths = resultSet.getInt(6);
}
public String getDate() {
return date;
}
public void setDate(String date) {
this.date = date;
}
public String getCountry() {
return country;
}
public void setCountry(String country) {
this.country = country;
}
public String getState() {
return state;
}
public void setState(String state) {
this.state = state;
}
public String getFips() {
return fips;
}
public void setFips(String fips) {
this.fips = fips;
}
public int getCases() {
return cases;
}
public void setCases(int cases) {
this.cases = cases;
}
public int getDeaths() {
return deaths;
}
public void setDeaths(int deaths) {
this.deaths = deaths;
}
}
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class MapSQL extends Mapper<LongWritable, Text, NullWritable, BeanSQL> {
BeanSQL v = new BeanSQL();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 获取每行数据进行字段拆分
String[] fields = value.toString().split(",");
// 判断
if (fields[0].equals("date") || fields.length < 6) return;
// 封装
v.set(
fields[0],
fields[1],
fields[2],
fields[3],
(int)Double.parseDouble(fields[4]),
(int)Double.parseDouble(fields[5])
);
// 写出
context.write(NullWritable.get(),v);
System.out.println(v.toString());
}
}
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class ReduceSQL extends Reducer<NullWritable, BeanSQL, BeanSQL, NullWritable> {
@Override
protected void reduce(NullWritable key, Iterable<BeanSQL> values, Context context) throws IOException, InterruptedException {
// 写出
for (BeanSQL bean:values){
context.write(bean,key);
System.out.println(bean);
}
}
}
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.db.DBConfiguration;
import org.apache.hadoop.mapreduce.lib.db.DBOutputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
public class DriverSQL {
public static void main(String[] args) {
try {
// 创建job
Configuration conf = new Configuration();
// 创建数据库连接
DBConfiguration.configureDB(
conf,
"com.mysql.jdbc.Driver",
"jdbc:mysql://localhost:3306/mr",
"root","123456"
);
Job job = Job.getInstance(conf);
// 配置Map、reduce、driver类
job.setMapperClass(MapSQL.class);
job.setMapOutputKeyClass(NullWritable.class);
job.setMapOutputValueClass(BeanSQL.class);
job.setReducerClass(ReduceSQL.class);
job.setOutputKeyClass(BeanSQL.class);
job.setOutputValueClass(NullWritable.class);
job.setJarByClass(DriverSQL.class);
// 设置输入文件路径
Path input = new Path(
"G:\\Projects\\IdeaProject-C\\MapReduce\\src\\main\\java\\美国疫情\\data\\us_counties_covid19_daily.csv"
);
FileInputFormat.setInputPaths(job,input);
// 设置输出目标为数据库
job.setOutputFormatClass(DBOutputFormat.class);
// String[] fields = {"date","country","state","fips","cases","deaths"};
DBOutputFormat.setOutput(job,"usa","date","country","state","fips","cases","deaths");
// 提交job
System.exit(job.waitForCompletion(true) ? 0:1);
} catch (Exception e) {
e.printStackTrace();
}
}
}
date,county,state,fips,cases,deaths
2020-01-21,Snohomish,Washington,53061.0,1,0.0
2020-01-22,Snohomish,Washington,53061.0,1,0.0
2020-01-23,Snohomish,Washington,53061.0,1,0.0
2020-01-24,Cook,Illinois,17031.0,1,0.0
2020-01-24,Snohomish,Washington,53061.0,1,0.0
2020-01-25,Orange,California,6059.0,1,0.0
2020-01-25,Cook,Illinois,17031.0,1,0.0
2020-01-25,Snohomish,Washington,53061.0,1,0.0
2020-01-26,Maricopa,Arizona,4013.0,1,0.0
2020-01-26,Los Angeles,California,6037.0,1,0.0
2020-01-26,Orange,California,6059.0,1,0.0
2020-01-26,Cook,Illinois,17031.0,1,0.0
2020-04-03,Nash,North Carolina,37127.0,14,0.0
2020-04-03,New Hano原始数据集比较大,这里截取部分

这里做了改动,将创建数据库连接放在了获取job的前面,运行后还是报错,但是比之前的报错java.io.IOException多了点内容,显示不能够连接到数据据库服务,但是navicate可以连接,按照 https://blog.csdn.net/qq_27387133/article/details/106277653 的方法后,还是不行(也许有的可以)。然后就想着换种方式,看看能不能传到虚拟机的数据库中。


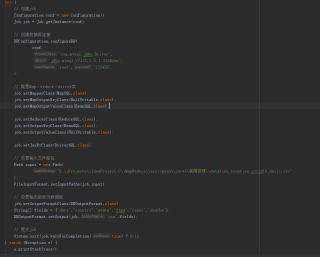
创建好表后,然后再改一下数据库连接地址,运行后可以了!


发现应该是数据库的问题,本地装的8.0的,虚拟机装的5.7的,程序环境中的mysql-connector是5.1.40的。