python爬虫入门请教问题
大佬们,我想问一下,为什么python保存到本地的HTML页面用浏览器打开后很多东西都加载不出来呢,页面的布局也很不一样,下面是我写的保存B站HTML页面
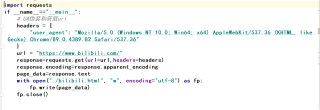
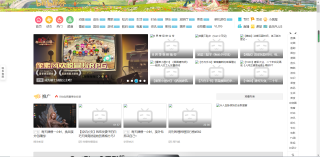
然后爬出来的HTML打开的页面是这个样子的
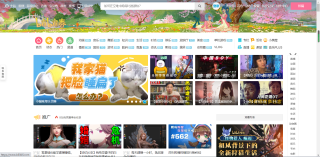
但是他原页面是这个样子的
这是怎么回事啊,求大佬们指点!!!
- 你只是爬了个静态的,网页还有很多动态元素;
- 有一些是相对路径的,在对方的服务器上,你本地无法加载到。
- 你看百度的快照,跟你这种差不多,如果你想完全一样的页面,除了一些小网站,其他基本不可能。
一个网页中的内容不是都包含在一个html文件中,它要加载一些外部文件,比如图片,视频,css样式表,js代码。
这些外部文件的加载地址大多用的都是相对地址,相对地址就是从当前html文件存放的位置相对查找。
你只保存了html文件,那些外部文件没有保存,通过相对地址自然查找不到。
那这样会不会影响xpath定位后面的图片的src啊,我后面想爬取图片的时候,用xpath-helper获取图片定位,但是xpath解析出来就是空的,是不是这个原因
您好,我是有问必答小助手,你的问题已经有小伙伴为您解答了问题,您看下是否解决了您的问题,可以追评进行沟通哦~
如果有您比较满意的答案 / 帮您提供解决思路的答案,可以点击【采纳】按钮,给回答的小伙伴一些鼓励哦~~
ps:问答VIP仅需29元,即可享受5次/月 有问必答服务,了解详情>>>https://vip.csdn.net/askvip?utm_source=1146287632