python数据集异常符号的处理和缺失值填补的问题
大家好!我在尝试使用df.replace函数进行数据集中异常符号的替换和,但是出现了以下几个问题。
首先我创建一个简单的数据集如下:
example_data = {'A': ['1', '-', '<0.9'],
'B': ['3', '19/20','$25']
}
example_df = pd.DataFrame (example_data, columns = ['A','B'])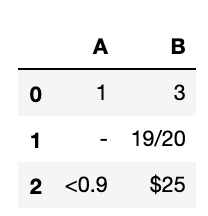
接下来使用replace函数进行特殊符号的去除。即把 - / < $ 等特殊符号去除只保留数字。
example_df = example_df.replace('/','', regex=True)
example_df = example_df.replace('$','', regex=True)#只有符号$无法去除?
example_df = example_df.replace('<','', regex=True)
example_df = example_df.replace('-','', regex=True)
example_df问题1:使用replace函数无法去除符号“$”。请问这种情况应该怎么解决?
而且这种办法只适合知道异常符号是什么且异常符号种类很少的情况,如果想一次性替换掉所有特殊符号呢?我查询了很多方法,以下这种方法最接近,但是它一次性去掉了包含特殊符号的单元格的值。
for col in example_df.columns:
example_df[col].replace(regex=True, inplace=True, to_replace=r'[-@#&$%+/\*<>=]', value=np.nan)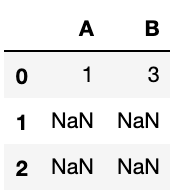
问题2: 请问如何一次性将所有特殊符号去除,并保留其所在单元格内的其他内容?
经过处理得到如下数据集:
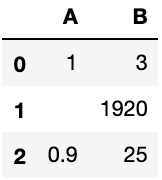
我想把缺失值使用列中位数进行填补,但是却报错“could not convert string to float: '' ”。好像是因为我把特殊符号替换成了空字符串?
for col in example_df.columns[0:]:
fill_val = example_df[col].dropna().astype(float).median()
example_df[col].fillna(fill_val,inplace=True)问题3: 请问大家这种没有办法转换成数值型的情况下应该怎么用中位数或者平均数填补缺失值?是不是我替换特殊符号的方法还是有问题的?
还有一个小问题~我发现如果一个单元格内只有特殊符号,那么使用None进行替换后,他们不会变成空,反而会自动填补上一行的值。请问这个是为什么呢?
#如果一个变量中只有一个特殊符号,填补成为空白之后会自动填补上一行的值?
example_df = example_df.replace('-',None, regex=True)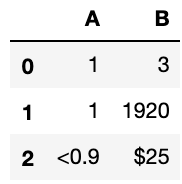
多谢各位大神!感激不尽!
这个是正则表达式,$在正则表达式中表示一行或整个文本的结尾。
要替换 $ 应该写成 r'\$'
example_df = example_df.replace(r'\$','', regex=True)#只有符号$无法去除?
如果想一次性替换掉所有特殊符号
example_df = example_df.replace(r'[\-@#&\$%+/\\*<>=]','', regex=True)
# 第3个问题要把空字符串替换成pd.NA
example_df = example_df.replace(r'^\s*$',pd.NA, regex=True)
import pandas as pd
example_data = {'A': ['1', '-', '<0.9'],
'B': ['3', '19/20','$25']
}
example_df = pd.DataFrame (example_data, columns = ['A','B'])
example_df = example_df.replace(r'[\-@#&\$%+/\\*<>=]','', regex=True)
example_df = example_df.replace(r'^\s*$',pd.NA, regex=True)
print(example_df)
for col in example_df.columns[0:]:
fill_val = example_df[col].dropna().astype(float).median()
example_df[col].fillna(fill_val,inplace=True)
print(example_df)
将value值设置为空字符,就可得到想要的结果,修改如下:
#原代码
"""
for col in example_df.columns:
example_df[col].replace(regex=True, inplace=True, to_replace=r'[-@#&$%+/\*<>=]', value=np.nan)
"""
#改为:
for col in example_df.columns:
example_df[col].replace(regex=True, inplace=True,
to_replace=r'[-@#&$%+/\*<>=]',value='')
用个比较繁琐不过比较好理解的方法:
1 $ 算是特殊的字符, 替换时前面需要加个反斜杠
2 不用正则表达式, 通过applymap对每个单元格的值进行替换
3 替换后的数据先转成数值型, 再填充均值
import pandas as pd
import numpy as np
dic = {'A': ['1', '-', '<0.9'],'B': ['3', '19/20','$25']}
data = pd.DataFrame (dic, columns = ['A','B'])
# 对$ 进行替换
data['B'].str.replace('\$','')
# 对所有进行替换
data_re = data.applymap(lambda x: x.replace('$','').replace('/','').replace('<','').replace('-',''))
# 填充均值
data_re2 = data_re.apply(lambda x: x.replace('',np.nan)).astype('float').apply(lambda x:x.fillna(x.mean()))
您好,我是问答小助手,你的问题已经有小伙伴为您解答了问题,您看下是否解决了您的问题,可以追评进行沟通哦~
如果有您比较满意的答案 / 帮您提供解决思路的答案,可以点击【采纳】按钮,给回答的小伙伴一些鼓励哦~~
ps:问答VIP仅需29元,即可享受5次/月 有问必答服务,了解详情>>> https://vip.csdn.net/askvip?utm_source=1146287632