关于python中pandas索引取值问题
Order = pd.read_csv('Order.csv', header=None, names=['date', 'time', 'city', 'id', 'zl', 'xse', 'sl', 'zk', 'lr'])
sorted = Order.groupby(['zl','city']).agg(sum=('xse','sum')).sort_values(by='sum')
df =sorted.sort_values(['zl','city'])
print(df)这种代码输出:
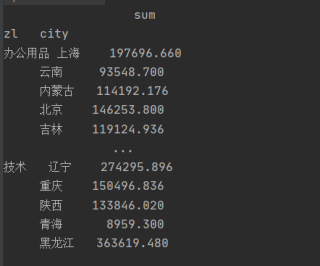
他的index索引:
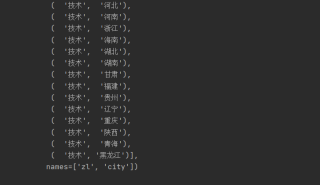
像这种index有两列,我应该怎么用pandas来提取 (zl="技术”) 后面xse的数值。
修改了一下代码,看看这个是不是你要的
Order = pd.read_csv('Order.csv', header=None, names=['date', 'time', 'city', 'id', 'zl', 'xse', 'sl', 'zk', 'lr'])
sorted = Order.groupby(['zl','city']).agg(sum=('xse','sum')).sort_values(by='sum')
df =sorted.sort_values(['zl','city'])
print(df.loc[['技术']])
Order = pd.read_csv('Order.csv', header=None, names=['date', 'time', 'city', 'id', 'zl', 'xse', 'sl', 'zk', 'lr'])
sorted = Order.groupby(['zl','city']).agg(sum=('xse','sum')).sort_values(by='sum')
df =sorted.sort_values(['zl','city'])
print(df.loc[['技术']])
题主是这个意思吗?
索引里面传入元组的格式, 类似于这样, 或者 用reset_index() 将索引变成列, 然后按列的格式再筛选
import pandas as pd
import numpy as np
data = pd.read_excel('c:/users/yyz/desktop/123.xlsx')
result =data.groupby(['类型','地名'])['值'].sum()
print(result[('技术',)])
print(result[('技术','北京')])
如果是对索引进行排序, 试试这样
import pandas as pd
import numpy as np
data = pd.read_excel('c:/users/yyz/desktop/123.xlsx')
result =data.groupby(['类型','地名'])['值'].sum().sort_index(level=0,ascending=False) # 因为是多级索引 也可以level =[0,1]
print(result[('技术',)])
print(result[('技术','北京')])
您好,我是问答小助手,你的问题已经有小伙伴为您解答了问题,您看下是否解决了您的问题,可以追评进行沟通哦~
如果有您比较满意的答案 / 帮您提供解决思路的答案,可以点击【采纳】按钮,给回答的小伙伴一些鼓励哦~~
ps:问答VIP仅需29元,即可享受5次/月 有问必答服务,了解详情>>> https://vip.csdn.net/askvip?utm_source=1146287632