基于tensorflow的模型做预测时,cpu占用率过高,如何降低程序的cpu占用率?
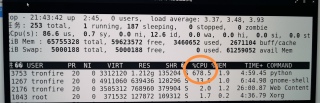
如图,在cpu服务器,liunux系统下跑,基于tensorflow的模型做预测时,cpu占用率过高,最多达到了700%,严重影响服务器上其他程序的运行,请问可以怎么改程序,降低程序的cpu占用率?
def test(self, height, width, input_path, output_path,checkpoint_path):
imgsName = sorted(os.listdir(input_path))#遍历文件夹中的所有图像
H, W = height, width
inp_chns = 3 if self.args.model == 'color' else 1
self.batch_size = 1 if self.args.model == 'color' else 1
model_name = "deblur.model"
ckpt_name = model_name + '-' + '15000'
tf.reset_default_graph()
graph = tf.get_default_graph()
inputs = tf.placeholder(shape=[self.batch_size, H, W, inp_chns], dtype=tf.float32) #输入占位符
outputs = self.generator(inputs, reuse=False)#建立计算图
saver = tf.train.Saver(tf.global_variables(), max_to_keep=2)
sess=tf.Session(graph=graph,config=tf.ConfigProto(device_count={"CPU": 1},allow_soft_placement=True,inter_op_parallelism_threads=1,intra_op_parallelism_threads=1,use_per_session_threads=True))#设置sess
saver.restore(sess, os.path.join(checkpoint_path, 'B5678-1-60-noise7', ckpt_name))#加载训练的模型
for imgName in imgsName: #循环处理之前遍历的图像
blur =cv2.imread(os.path.join(input_path, imgName),-1)#读入图
h, w = blur.shape
x=h//512
#print(x)
y=w//512
#print(y)
if x>y:
blur = np.pad(blur, ((0, ((x+1)*512 - h)), (0,((x+1)*512 - w))), 'edge') #把图像扩充为512*512的整数倍方便裁切
after_deblur=np.zeros((((x+1)*512), ((x+1)*512))) #建立相同大小空矩阵
if x<=y:
blur = np.pad(blur, ((0, ((y+1)*512 - h)), (0,((y+1)*512 - w))), 'edge') #把图像扩充为512*512的整数倍方便裁切
after_deblur=np.zeros((((y+1)*512), ((y+1)*512)))#建立相同大小空矩阵
#把图像切分成512*512的小图,依次送入神经网络得到结果
starttotal = time.time()
for ii in range(x+1):
for jj in range(y+1):
blurPad = blur[ii * 512:(ii + 1) * 512, jj * 512:(jj + 1) * 512] #按顺序裁切成512*512的图像块
blurPad = np.expand_dims(blurPad, -1)
blurPad = np.expand_dims(blurPad, 0)
if self.args.model != 'color':
blurPad = np.transpose(blurPad, (3, 1, 2, 0))
start = time.time()
deblur = sess.run(outputs, feed_dict={inputs: blurPad / 4095.0})#把图像块送入计算图中sess.run计算
duration = time.time() - start
res = deblur[-1]
res = np.clip(res, a_min=0, a_max=1)
if self.args.model != 'color':
res = np.transpose(res, (3, 1, 2, 0))
res = res[0, :, :, :] * 4095.0
res = (res.astype(np.uint16))
res = np.squeeze(res)
after_deblur = (after_deblur.astype(np.uint16))
after_deblur[ii * 512:(ii + 1) * 512, jj * 512:(jj + 1) * 512]=res #用计算得到的结果替换空矩阵相同位置的值
durationtotal = time.time() - starttotal
print('total time use %4.3fs' % (durationtotal))
#print(after_deblur.shape)
after_deblur = after_deblur[:h, :w]
after_deblur = np.clip(after_deblur, a_min=0, a_max=4095)
#print(after_deblur.shape)
imtiff = Image.fromarray(after_deblur)
imtiff.save(os.path.join(output_path,imgName)) #写出图像
sess.close()
del sess
楼主,看下这两个方法能不能减少内存?我看你写的那个排序,imgsName = sorted(os.listdir(input_path))并没有起到排序的作用,正确的排序我写在代码里了,你也可以审视一下是否需要排序,如果不需要,也可以减少一些内存
#第1种
def test(self, height, width, input_path, output_path,checkpoint_path):
#imgsName = sorted(os.listdir(input_path))#遍历文件夹中的所有图像
from glob import glob
input_path = glob(path +"\*") #*.jpg
input_path.sort(key=lambda x:eval(os.path.basename(x).split(".")[0])) #直接返回路径和名称,不用os.path.join(input_path, imgName)
imgsName = iter(tuple(input_path)) #遍历文件夹中的所有图像
H, W = height, width
inp_chns = 3 if self.args.model == 'color' else 1
self.batch_size = 1 if self.args.model == 'color' else 1
model_name = "deblur.model"
ckpt_name = model_name + '-' + '15000'
tf.reset_default_graph()
graph = tf.get_default_graph()
inputs = tf.placeholder(shape=[self.batch_size, H, W, inp_chns], dtype=tf.float32) #输入占位符
outputs = self.generator(inputs, reuse=False)#建立计算图
saver = tf.train.Saver(tf.global_variables(), max_to_keep=2)
sess=tf.Session(graph=graph,config=tf.ConfigProto(device_count={"CPU": 1},allow_soft_placement=True,inter_op_parallelism_threads=1,intra_op_parallelism_threads=1,use_per_session_threads=True))#设置sess
saver.restore(sess, os.path.join(checkpoint_path, 'B5678-1-60-noise7', ckpt_name))#加载训练的模型
for imgName in imgsName: #循环处理之前遍历的图像
blur =cv2.imread(imgName,-1)#读入图
h, w = blur.shape
x=h//512
#print(x)
y=w//512
#print(y)
if x>y:
blur = np.pad(blur, ((0, ((x+1)*512 - h)), (0,((x+1)*512 - w))), 'edge') #把图像扩充为512*512的整数倍方便裁切
after_deblur=np.zeros((((x+1)*512), ((x+1)*512))) #建立相同大小空矩阵
if x<=y:
blur = np.pad(blur, ((0, ((y+1)*512 - h)), (0,((y+1)*512 - w))), 'edge') #把图像扩充为512*512的整数倍方便裁切
after_deblur=np.zeros((((y+1)*512), ((y+1)*512)))#建立相同大小空矩阵
#把图像切分成512*512的小图,依次送入神经网络得到结果
starttotal = time.time()
for ii in range(x+1):
for jj in range(y+1):
blurPad = blur[ii * 512:(ii + 1) * 512, jj * 512:(jj + 1) * 512] #按顺序裁切成512*512的图像块
blurPad = np.expand_dims(blurPad, -1)
blurPad = np.expand_dims(blurPad, 0)
if self.args.model != 'color':
blurPad = np.transpose(blurPad, (3, 1, 2, 0))
start = time.time()
deblur = sess.run(outputs, feed_dict={inputs: blurPad / 4095.0})#把图像块送入计算图中sess.run计算
duration = time.time() - start
res = deblur[-1]
res = np.clip(res, a_min=0, a_max=1)
if self.args.model != 'color':
res = np.transpose(res, (3, 1, 2, 0))
res = res[0, :, :, :] * 4095.0
res = (res.astype(np.uint16))
res = np.squeeze(res)
after_deblur = (after_deblur.astype(np.uint16))
after_deblur[ii * 512:(ii + 1) * 512, jj * 512:(jj + 1) * 512]=res #用计算得到的结果替换空矩阵相同位置的值
durationtotal = time.time() - starttotal
print('total time use %4.3fs' % (durationtotal))
#print(after_deblur.shape)
after_deblur = after_deblur[:h, :w]
after_deblur = np.clip(after_deblur, a_min=0, a_max=4095)
#print(after_deblur.shape)
imtiff = Image.fromarray(after_deblur)
imtiff.save(os.path.join(output_path,imgName)) #写出图像
sess.close()
del sess
#第二种
def test(self, height, width, input_path, output_path,checkpoint_path):
#imgsName = sorted(os.listdir(input_path))#遍历文件夹中的所有图像
input_image = os.listdir(path)
input_image.sort(key=lambda x:eval(x.split(".")[0]))
imgsName = iter(tuple(input_image))
H, W = height, width
inp_chns = 3 if self.args.model == 'color' else 1
self.batch_size = 1 if self.args.model == 'color' else 1
model_name = "deblur.model"
ckpt_name = model_name + '-' + '15000'
tf.reset_default_graph()
graph = tf.get_default_graph()
inputs = tf.placeholder(shape=[self.batch_size, H, W, inp_chns], dtype=tf.float32) #输入占位符
outputs = self.generator(inputs, reuse=False)#建立计算图
saver = tf.train.Saver(tf.global_variables(), max_to_keep=2)
sess=tf.Session(graph=graph,config=tf.ConfigProto(device_count={"CPU": 1},allow_soft_placement=True,inter_op_parallelism_threads=1,intra_op_parallelism_threads=1,use_per_session_threads=True))#设置sess
saver.restore(sess, os.path.join(checkpoint_path, 'B5678-1-60-noise7', ckpt_name))#加载训练的模型
for imgName in imgsName: #循环处理之前遍历的图像
blur =cv2.imread(os.path.join(input_path, imgName),-1)#读入图
h, w = blur.shape
x=h//512
#print(x)
y=w//512
#print(y)
if x>y:
blur = np.pad(blur, ((0, ((x+1)*512 - h)), (0,((x+1)*512 - w))), 'edge') #把图像扩充为512*512的整数倍方便裁切
after_deblur=np.zeros((((x+1)*512), ((x+1)*512))) #建立相同大小空矩阵
if x<=y:
blur = np.pad(blur, ((0, ((y+1)*512 - h)), (0,((y+1)*512 - w))), 'edge') #把图像扩充为512*512的整数倍方便裁切
after_deblur=np.zeros((((y+1)*512), ((y+1)*512)))#建立相同大小空矩阵
#把图像切分成512*512的小图,依次送入神经网络得到结果
starttotal = time.time()
for ii in range(x+1):
for jj in range(y+1):
blurPad = blur[ii * 512:(ii + 1) * 512, jj * 512:(jj + 1) * 512] #按顺序裁切成512*512的图像块
blurPad = np.expand_dims(blurPad, -1)
blurPad = np.expand_dims(blurPad, 0)
if self.args.model != 'color':
blurPad = np.transpose(blurPad, (3, 1, 2, 0))
start = time.time()
deblur = sess.run(outputs, feed_dict={inputs: blurPad / 4095.0})#把图像块送入计算图中sess.run计算
duration = time.time() - start
res = deblur[-1]
res = np.clip(res, a_min=0, a_max=1)
if self.args.model != 'color':
res = np.transpose(res, (3, 1, 2, 0))
res = res[0, :, :, :] * 4095.0
res = (res.astype(np.uint16))
res = np.squeeze(res)
after_deblur = (after_deblur.astype(np.uint16))
after_deblur[ii * 512:(ii + 1) * 512, jj * 512:(jj + 1) * 512]=res #用计算得到的结果替换空矩阵相同位置的值
durationtotal = time.time() - starttotal
print('total time use %4.3fs' % (durationtotal))
#print(after_deblur.shape)
after_deblur = after_deblur[:h, :w]
after_deblur = np.clip(after_deblur, a_min=0, a_max=4095)
#print(after_deblur.shape)
imtiff = Image.fromarray(after_deblur)
imtiff.save(os.path.join(output_path,imgName)) #写出图像
sess.close()
del sess
with tf.Session(config=tf.ConfigProto(
device_count={"CPU":12},
inter_op_parallelism_threads=1,
intra_op_parallelism_threads=1,
gpu_options=gpu_options,
)) as sess:在Session定义时,ConfigProto中可以尝试指定下面三个参数:
- device_count, 告诉tf Session使用CPU数量上限,如果你的CPU数量较多,可以适当加大这个值
- inter_op_parallelism_threads和intra_op_parallelism_threads告诉session操作的线程并行程度,如果值越小,线程的复用就越少,越可能使用较多的CPU核数。如果值为0,TF会自动选择一个合适的值。
如果是Intel的CPU,可以把Intel的MKL包编译进TensorFlow中,以增加训练效率。
你的服务器多少c的? 700 已经严重影响,难道是8c 的?那你就设置少用几个C
1、从代码层修改,分批处理,效果一般
2、用GPU,没有就算了
3、用 nice 命令,从服务器上设置进程的优先级
4、设置device_count,告诉tf-Session可以使用的CPU数量上限
with tf.Session(config=tf.ConfigProto(device_count={"CPU":6}))
https://blog.csdn.net/bill20100829/article/details/115016611
楼主,文件夹里的文件多吗?
还有这块,相同的操作,你可以用几个变量表示,减少了每次不必要的乘法,这样每次循环都减少了时间和空间,三层循环,时空复杂度本身就高。

有完整的代码嘛,我想看看
700%就是占了7个线程,你的电脑肯定不止7个线程,没事的。我的电脑是6核12线程的,跑大数据经常用10个线程,CPU占1000%,还剩下2个线程一样可以干其他活。你试试。
这个我都可以直接给你搞定