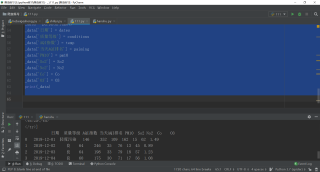
import requests
from bs4 import BeautifulSoup
import pandas as pd
def method_name():
# url = 'http://www.tianqihoubao.com/aqi/xingtai-202102.html'
years = ['2013','2014', '2015', '2026','2017','2018', '2019', '2020']
months = ['1', '2', '3', '4', '5', '6', '7', '8', '9', '10', '11', '12']
# for i in years:
# for j in months:
# a = 'http://www.tianqihoubao.com/aqi/xingtai-'+str(i)+str(j)+'.html'
# print(a)
# pass
# pass
# for i in years:
# for j in months:
# a = 'http://www.tianqihoubao.com/aqi/xingtai-{}{}.html' .format(i,j)
# print(a)
# pass
# pass
for i in months:
a = 'http://www.tianqihoubao.com/aqi/xingtai-2019{}.html' .format(i)
print(a)
global tr_list
resp = requests.get(a)
html = resp.content.decode('gbk')
# 数据提取
soup = BeautifulSoup(html, 'html.parser')
tr_list = soup.find_all('tr')
print(tr_list)
#获取网页源代码
method_name()
dates,conditions,temp,paiming= [],[],[],[]
pm10,So2,No2,Co,O3 = [],[],[],[],[]
for data in tr_list[1:]:
sub_data = data.text.split()
dates.append(sub_data[0])
conditions.append(''.join(sub_data[1]))
temp.append(''.join(sub_data[2]))
paiming.append(''.join(sub_data[3]))
pm10.append(''.join(sub_data[4]))
So2.append(''.join(sub_data[5]))
No2.append(''.join(sub_data[6]))
Co.append(''.join(sub_data[7]))
O3.append(''.join(sub_data[8]))
_data = pd.DataFrame()
_data['日期'] = dates
_data['质量等级'] = conditions
_data['AQI指数'] = temp
_data['当天AQI排名'] = paiming
_data['PM10'] = pm10
_data['So2'] = So2
_data['No2'] = No2
_data['Co'] = Co
_data['O3'] = O3
print(_data)