初学python爬虫,爬取不到网页的阅读数是怎么回事?求大神解答
import scrapy
class JobboleSpider(scrapy.Spider):
name = 'jobbole'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/gncj/170427.html']
def parse(self, response):
re_selector = response.xpath("/html/body/div[3]/div[1]/div[3]/div[1]/h1")
title = response.xpath('//div[@class="article-head"]/h1/text()').extract()
create_time = response.xpath("//div[@class='article-detail bgc-fff']/div[1]/div/div/span/text()").extract()[0]
read_num = response.xpath("/html/body/div[3]/div[1]/div[3]/div[1]/div/div/span[2]/text()").extract()read_num无法提取数据
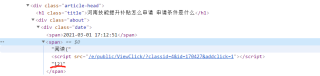
我通过xpath只能提取到")",这是为啥?请教!!!!
数据是js动态渲染的,scrapy需结合splash使用,用selenium速度虽慢点,但是对js加载数据的获取准确性较高。
driver.implicitly_wait(5)
#page=driver.page_source
read_num = driver.find_element_by_xpath(
"/html/body/div[3]/div[1]/div[3]/div[1]/div/div/span[2]").text
print(read_num)
##output:
阅读(18)
原先给你的只是思路和代码片断,完整代码如下:
#from bs4 import BeautifulSoup
from selenium import webdriver
#from selenium.webdriver.support.ui import WebDriverWait
#from selenium.webdriver.common.by import By
#from selenium.webdriver.support import expected_conditions as EC
from time import sleep
options = webdriver.ChromeOptions()
#options.add_argument('--disable-blink-features=AutomationControlled')
options.add_argument("--incognito")
options.add_argument('--start-maximized')
options.add_argument('--disable-extensions')
options.add_argument('--headless')
driver = webdriver.Chrome(options=options)
#driver.maximize_window()
driver.get('http://blog.jobbole.com/gncj/170427.html')
driver.implicitly_wait(5)
#page=driver.page_source
title = driver.find_element_by_xpath(
"/html/body/div[3]/div[1]/div[3]/div[1]/h1").text.strip()
create_time = driver.find_element_by_xpath(
"//div[@class='article-detail bgc-fff']/div[1]/div/div/span").text.strip()
read_num = driver.find_element_by_xpath(
"/html/body/div[3]/div[1]/div[3]/div[1]/div/div/span[2]").text.strip()
print(title)
print(create_time)
print(read_num)
import scrapy
from selenium import webdriver
from time import sleep
webdriver.implicitly_wait(5)#page=driver.page_source
class JobboleSpider(scrapy.Spider):
name = 'jobbole'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/gncj/170427.html']
def parse(self, response):
re_selector = response.xpath("/html/body/div[3]/div[1]/div[3]/div[1]/h1")
title = response.xpath('//div[@class="article-head"]/h1/text()').extract()
create_time = response.xpath("//div[@class='article-detail bgc-fff']/div[1]/div/div/span/text()").extract()[0]
#read_num = response.xpath("/html/body/div[3]/div[1]/div[3]/div[1]/div/div/span[2]/text()").extract()[1]#提取的数据有问题。留待今后解决。
read_num = webdriver.find_element_by_xpath("/html/body/div[3]/div[1]/div[3]/div[1]/div/div/span[2]/text()").extract()
pass