python对json数据进行爬取,现有代码有点笨,代码是否有其他方法实现
代码如下
import requests
import json
import re
import jsonpath
import pandas as pd
headers = {
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36',
'Accept': '*/*',
'Referer': 'http://data.eastmoney.com/',
'Accept-Language': 'zh-CN,zh-TW;q=0.9,zh;q=0.8,en-US;q=0.7,en;q=0.6',
}
url = 'http://push2.eastmoney.com/api/qt/stock/fflow/kline/get?cb=jQuery1123010658079990618585_1613899835088&lmt=0&klt=1&fields1=f1%2Cf2%2Cf3%2Cf7&fields2=f51%2Cf52%2Cf53%2Cf54%2Cf55%2Cf56%2Cf57%2Cf58%2Cf59%2Cf60%2Cf61%2Cf62%2Cf63%2Cf64%2Cf65&ut=b2884a393a59ad64002292a3e90d46a5&secid=0.002594'
html = requests.get(url,headers = headers)
# content = html.text
# print(type(content))
content = re.findall(r'^jQuery\w+\((.+)\);$',html.text)[0]
data = json.loads(content)
# print(data)
net_amount_list1 = jsonpath.jsonpath(data, '$..0')
stock1 = net_amount_list1[1].split(',')
net_amount_list2 = jsonpath.jsonpath(data, '$..1')
stock2 = net_amount_list2[1].split(',')
# time = []
# time.append(stock1[0])
# time.append(stock2[0])
#
# a = []
# a.append(stock1[1])
# a.append(stock2[1])
datas = {'时间':[stock1[0],stock2[0]],
'主力净流入':[stock1[1],stock2[1]],
'超大单净流入':[stock1[5],stock2[5]],
'大单净流入':[stock1[4],stock2[4]],
'中单净流入':[stock1[3],stock2[3]],
'小单净流入':[stock1[2],stock2[2]]
}
# print(datas)
df = pd.DataFrame(datas)
df.to_excel('east_money.xlsx')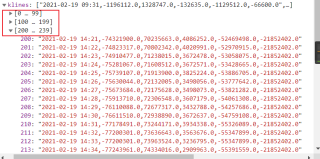
这是现有代码,只对其中两条数据进行了获取,但是json返回的数据有两百多条,感觉这样写有点笨,是否有更好的方法优化

返回要获取的数据如图
233
不需导入jsonpath,用列表表达式即可:
data = json.loads(content)['data']['klines']
#print(data)
datas = {'时间':[item.split(',')[0] for item in data],
'主力净流入': [item.split(',')[1] for item in data],
'小单净流入': [item.split(',')[2] for item in data],
'中单净流入': [item.split(',')[3] for item in data],
'大单净流入': [item.split(',')[4] for item in data],
'超大单净流入': [item.split(',')[5] for item in data]}
#导出所有数据。
df = pd.DataFrame(datas)
print(df)