python中如何计算每个流派每年各项指表的平均值
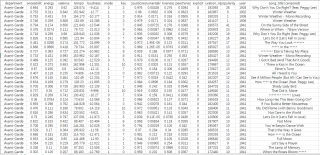
如图表所示,以Avant-Grade流派为例,该流派一共有多首歌曲,每首歌曲有十多种属性。
如果以一个流派一年内所发的歌曲各项数值的平均值来代表这个流派这一年的各项音乐属性值。
现在希望求各个流派已知的每年的音乐属性情况(因为要做随时间的属性变化趋势图),并最终导出为CSV文件,求大佬用代码解决一下这个问题
csv数据已上传至资源
###文件格式正常的话,应该可以通。有问题的话,把csv 上传上去,我再改
import pandas as pd
df=pd.read_csv('wenjian.csv')
df1=df.drop(['song_title(censored)'], axis = 1)
gp=df1.groupby(['department','year']).mean()
department=[]
year=[]
for n1,n2 in gp.index:
department.append(n1)
year.append(n2)
gp['department']=department
gp['year']=year
df2=gp.reset_index(drop=True)
df2.to_csv('out_wenjian.csv',index=0)
没看到上传资源

用这个代码:
cols为除了department,year,song_title(censored)以外的其他各属性名的列表
df1=df.groupby(['department','year'])[cols].agg(lambda x: sum(x)/len(x))
用例:
df = pd.DataFrame({'name': ['Alice']*5+['Bob']*5, 'salary': [25600, 33200, 28760, 42000, 43120, 36980, 38742, 69850, 57840, 74651],'worktime':[200,240,220,270,300,320,310,300,345,350],'project':[10,12,13,14,12,18,20,22,26,30], 'year': [2012,2013,2012,2012,2013,2013,2012,2012,2012,2013]}).set_index(['name'])
print(df)
df1=df.groupby(['name','year'])[['salary','worktime','project']].agg(lambda x: sum(x)/len(x))
print(df1)