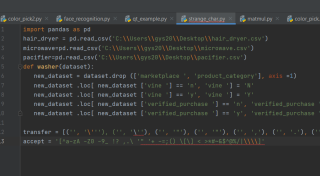
请问python代码中出现这个的原因是什么
import pandas as pd
hair_dryer = pd.read_csv('C:\\Users\\gys20\\Desktop\\hair_dryer.csv')
microwave=pd.read_csv('C:\\Users\\gys20\\Desktop\\microwave.csv')
pacifier=pd.read_csv('C:\\Users\\gys20\\Desktop\\pacifier.csv')
def washer(dataset):
new_dataset = dataset.drop (['marketplace ', 'product_category'], axis =1)
new_dataset .loc[ new_dataset ['vine '] == 'n', 'vine '] = 'N'
new_dataset .loc[ new_dataset ['vine '] == 'y', 'vine '] = 'Y'
new_dataset .loc[ new_dataset ['verified_purchase '] == 'n', 'verified_purchase '] = 'N'
new_dataset .loc[ new_dataset ['verified_purchase '] == 'y', 'verified_purchase '] = 'Y'
transfer = [('', '\'''), ('', '\''), ('', '"'), ('', '"'), ('', ','), ('', '.'), ('', '!'), ('', '...'), ('', '-'), ('', '-')]
accept = '[^a-zA -Z0 -9_ !? ,.\ '" '+ -=;() \[\] < >*#~&$^@%/|\\\\]'
##用我这个
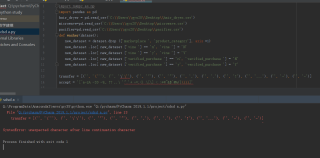
transfer = [('', '\'\''), ('', '\''), ('', '"'), ('', '"'), ('', ','), ('', '.'), ('', '!'), ('', '...'), ('', '-'), ('', '-')]
看看有没有中文字符还是其他的字符
('', '\''') 这个地方只有一个转义,单引号没结束。('', '\'\'') 这样就可以了
transfer = [('', '\'\''), ('', '\''), ('', '"'), ('', '"'), ('', ','), ('', '.'), ('', '!'), ('', '...'), ('', '-'), ('', '-')]
你换 PyCharm,看得更清楚。
@bj_0163_bj 还是不行

你这个地方没加转义
单引号作为字符每个都要转义
那个容易,下面的 regex 要他本人才明白。
例子:
r_validation = re.compile(r'''
^(?: # Capture from the start.
# Below is the same regex as above, but condensed.
# One tiny modification is that it allows empty values
# The first plus is replaced by an asterisk.
\s*([^,"']*?|"(?:[^"\\]|\\.)*"|'(?:[^'\\]|\\.)*')\s*(?:,|$)
)*$ # And don't stop until the end.
''', re.VERBOSE)transfer = [('', '\''),
('', '\''),
('', '"'),
('', '"'),
('', ','),
('', '.'),
('', '!'),
('', '...'),
('', '-'),
('', '-')]
# '[^a-zA -Z0 -9_ !? ,.\ '" '+ -=;() \[\] < >*#~&$^@%/|\\\\]'
accept = '[^a-zA -Z0 -9_ !? ,.\' " + -=;() [] < >*#~&$^@%/|'换行符“\” 后面存在空格。当换行符后面存在空格时,程序就会报错。