如何使用r语言批量读取pdf文件并进行数据梳理
有大批pdf格式的增值税发票,需读取并且从读取出的字符串中筛选并输出xlsx
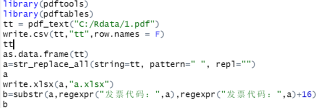
针对单一pdf我做了上图处理,但结果不理想,因为pdf文件不是标准的数据框,读取出来是这样的

请各位大神指点
不知道你这个问题是否已经解决, 如果还没有解决的话:如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 以帮助更多的人 ^-^
有大批pdf格式的增值税发票,需读取并且从读取出的字符串中筛选并输出xlsx
针对单一pdf我做了上图处理,但结果不理想,因为pdf文件不是标准的数据框,读取出来是这样的
请各位大神指点
不知道你这个问题是否已经解决, 如果还没有解决的话: