爬取网页时出现多个界面网址一致的情况,怎么解决?
爬取网页时出现多个界面网址一致的情况,且发送的请求除cookie里的token之外全部一致。。这种情况还能爬取么?
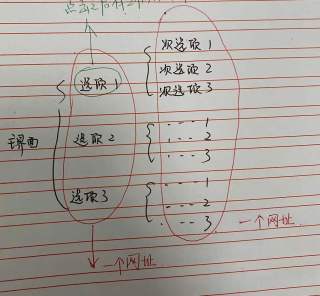
多界面网址一致画了个示意图
参考GPT和自己的思路:
针对出现多个界面网址一致的情况,可以通过以下几种方式解决:
1.分析网页参数:分析多个界面网址参数的不同之处,例如搜索关键词、翻页参数等,对其进行区分,从而不重复爬取相同的内容。
2.设置请求头信息:设置请求头信息,包括User-Agent、Referer等,让每个请求的头信息都有所不同,从而避免被服务器识别为机器人行为。
3.使用代理IP:使用代理IP,让每个请求的IP地址都不同,避免服务器识别为机器人行为。
4.等待时间隔:通过在请求之间设置休眠时间,不要一直发送请求,降低请求频率,避免被服务器识别为机器人行为。
总之,从多个方面入手,尝试不同的方法,可以避免出现多个界面网址一致的情况,从而更好的爬取网页内容。