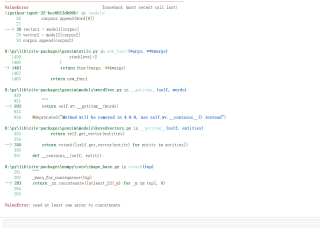
关于报错:need at least one array to concatenate
加载训练模型后,调用就报错,请问怎么解决急
from gensim.models import Word2Vec
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
KM = KMeans(n_clusters=2)
model1 = Word2Vec.load("chinese_model.model") #加载训练好的模型
corpus = []
corpus2= []
corpusx= []
B = model1.wv.index2word #获取word2vec训练过的词汇
gb = open('chinese',encoding='utf-8').readlines()
for word in gb[:30]: #为了方便,每个词库只取了前面30个单词
word = word.split('\n')
if word[0] in B:
corpus.append(word[0])
corpusx.append(word[0])
model2 = Word2Vec.load("english_model") #加载训练好的模型
B = model2.wv.index2word
fb = open('english').readlines()
for word in fb[:30]:
word = word.split('\n')
if word[0] in B:
corpus2.append(word[0])
corpusx.append(word[0])
vector1 = model1[corpus]
vector2 = model2[corpus2]
corpus.append(corpus2)
print(corpusx)
#vecter=vector1+vector2
python setup.py install
试试
从空数组进行连接会引发此错误,并且模型与加载状态dict之间存在大小不匹配(例如,类数2与81)。试试纠正尺寸不匹配会有所帮助?
您应该使用pip install -v -e .或python setup.py develop作为文档,因此当您直接在中修改代码时mmdet。如果使用python setup.py install,它将在您的环境Python的site-packages中生成一个包,这意味着您必须在更改内部内容之后再次构建它mmdet
造成学习失误的常见原因之一就是如此高的学习率造成了发散问题,有时降低学习率就可以解决问题。
参考:Scipy文档
对于您的情况,请检查feats_sc包含的内容。
您可以使用调试 pdb
python -m pdb <your-code>.py
(pdb) b fullpath/to/your-code.py:line-number-to-break
(pdb) c
c将继续直到遇到断点n将移至下一行b设定断点q退出
if corpus== 0:
return None