python中用pandas读取csv文件,求大佬解释为什么会报错
想通过匹配csv文件中某一列上某行的值是否等于给定的数从而获得这一行的所有数据,但是程序报错,请问是为什么呢
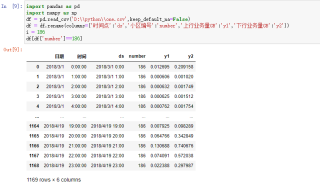
如下,想要获取“小区编号”列中小区编号为186的所有行
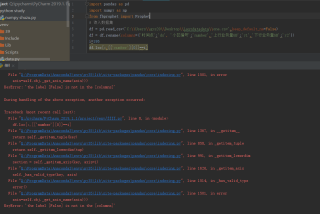
有没有源文件
这里应该不是pandas读csv的问题。而是你下面dataframe切片的问题。
你的列是Flase,但实际其实并没有False这一列存在
代码源文件已经上传至资源
你这个属于混用了, df.loc 第二个参数是列名, [[number[0]==186]] 这个结果是一个布尔值,把布尔值当做列名肯定找不到的。
df[df['number']==i] ##是等于i 的所有列数据。单一列小区编号的话就是
df[df['number']==i]['number']
df[df["number"]==i["number"]]
import pandas as pd
import numpy as np
df = pd.read_csv('D:\\python\\one.csv',keep_default_na=False)
df = df.rename(columns={'时间点':'ds','小区编号':'number','上行业务量GB':'y1','下行业务量GB':'y2'})
i = 186
df[df['number']==i]
import pandas as pd
df = pd.read_csv("C:\\Users\ECIDI\Desktop\\test.csv", encoding="gbk", keep_default_na=False)
print("修改列名前:\n", df)
df.rename(columns={"时间点": "ds", "小区编号": "number", "上行业务量GB": "y1", "下行业务量GB": "y2"}, inplace=True)
print("修改列名后:\n", df)
i = 2 # 样本数据不大,请见谅
result = df.loc[df["number"] == i]
print("按照number为i筛选后:\n", result)

列名修改那,你少了一点东西,貌似你那样是不行的
不好意思没看见,修改列名那你还重新赋值了