爬取内容中文乱码(这种“ú̿£ºËļ¾¶È¡°Ãº¡±·êÈý¡°½Ù¡±”)是怎么回事??
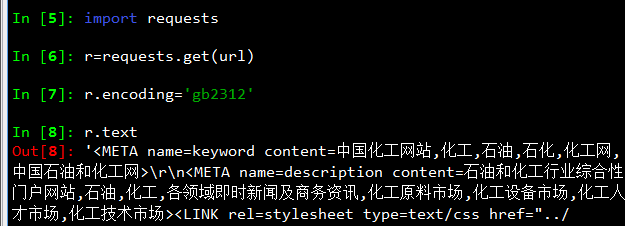
用scrapy爬取新闻网站内容,结果爬下来的是一堆乱码?gb2312、utf-8、gbk各种解码都试过了还是不行!
仍然是这种乱码 Á½ÓÍÖÜÎåÊÕ¸ß µÚÈý¼¾¶ÈÕÇ·ù´´Ò»Äê¶àÒÔÀ´×î´ó
储存入MongoDB也是这样
写入的时候别忘记加上 ensure_ascii=False
看了下,编码是gb2312,是asp.net写的伪静态网站。你再检查下
楼上的说得对的。gb2312.