python3中使用xpath无法定位,为什么一直返回空列表?
这几天在学习xpath的时候发现无法正确定位,返回的div_list都是空列表,但response信息是有正确返回的。可是怎么检查也没发现错误,希望大佬们麻烦看看,谢谢。
python版本3.6.
def select_html(self,response): #筛选网页信息
html = etree.HTML(response)
#分组
div_list = html.xpath("//div[@id='content-left']/div")
print(div_list)
for line in div_list:
data = {}
data['content'] = line.xpath(".//div[@class='content']/span/text()")
data['stats'] = line.xpath(".//div[@class='stats']/span[@class='stats-vote']/i/text()")
data['comment_number'] = line.xpath(".//span[@class='stats-comments']/a/i/text()")
data['img'] = 'https:'+ line.xpath(".//div[@class='thumb']/a/img/@src")
爬的是糗事百科的内容,下面是糗事百科的html截图: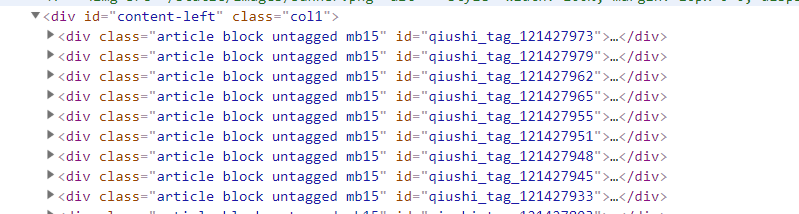
另附上糗百原址:
https://www.qiushibaike.com/hot/page/
最后一句会报错,去掉最后一句正常运行,可以参考下我的代码看看问题出现在哪:
from lxml import etree
import requests
url = 'https://www.qiushibaike.com/hot/'
r = requests.get(url)
try:
r.raise_for_status()
html = etree.HTML(r.text)
div_list = html.xpath("//div[@id='content-left']/div")
for line in div_list:
data = {}
data['content'] = line.xpath(".//div[@class='content']/span/text()")
data['stats'] = line.xpath(".//div[@class='stats']/span[@class='stats-vote']/i/text()")
data['comment_number'] = line.xpath(".//span[@class='stats-comments']/a/i/text()")
# data['img'] = 'https:'+ line.xpath(".//div[@class='thumb']/a/img/@src") # 这一句会报错
print(data)
except:
print('获取网页失败')
←如果以下回答对你有帮助,请点击右边的向上箭头及采纳下答案
div_list = html.xpath("//div[@id='content-left']/div")你要div的list应该是html.xpath("//div[@id='content-left']"),后面再加div就是单独一个了
问题解决了,一直解码response都是用的都是 response.content.decode(.....)。也没出现爬不到的问题。
现在用了response.text就问题解决了,无语。